陳巍談芯:本文將以OpenAI GPT-4 技術報告為基礎,介紹GPT-4的特征和訓練信息。作者本人曾擔任華為系自然語言處理《 NLP 》企業的首席科學家。
在2023年3月14日,OpenAI發佈了他們最新的NLP大作,GPT-4。《大概是致敬圓周率?》GPT-4的技術報告裡把OpenAI團隊作為唯一作者。《當然Altman特別提到了Jakub Pachocki在預訓練方面突出的領導能力和技術遠見》參與項目的有數百人,堪稱新時代的AI登月工程。
。")

GPT-4更多深入技術解讀,請看
1 能看明白圖梗的大型多模態模型
與ChatGPT稍有不同,GPT-4 是一個大型多模態模型《輸入圖像和文本,輸出文本輸出》。其中GPT是生成式預訓練模型的縮寫。大型多模態模型可以廣泛用於對話系統、文本摘要和機器翻譯。一般情況下,大型多模態模型包括額外的視覺語言模型組件《VLM》。
GPT-4實際上是在去年8月完成訓練的,直到2023年3月14日才發佈。在發佈之前,OpenAI一直在對該模型進行對抗性測試和改進。《防止GPT-4亂噴》。
GPT-4的內容窗口能支持多達32,000個token《相當於24000單次或48頁文本》

GPT家族內容窗口對比

但更為有趣的是GPT-4已經能看懂一些圖梗了,不再僅僅是對話助手。當然這離大家期待的看懂視頻還有一段距離。
2 名為GPT-4的考試小能手
據OpenAI介紹,雖然目前GPT-4在現實場景中的能力可能不如人類,但在各種專業和學術考試上表現出明顯超越人類水平的能力,包括大家熟悉的GRE考試,堪稱考試小能手。
這對孩子們是不是一個壞消息?例如,GPT-4在模擬律師考試中,分數排在應試者的前 10%左右。《估計律師們要首先抓狂》GPT-4也優於現有的其他語言模型。相比之下,GPT-3.5 的得分則在倒數10% 附近。如果GPT-4來做中國的高考卷,是不是能上北大清華了?甚至斯坦福博士說GPT-4已經可以考上斯坦福了。

斯坦福博士表示GPT-4已經可以考上斯坦福
典型的成績包括:
SAT《美國高考》: 1410/1600《前 6%》。
美國統一律師資格考試(MBE+MEE+MPT):298/400《前 10%》。
AP《美國大學預科考試》:生物學、微積分、宏觀經濟學、心理學、統計學和歷史的大學預修高中考試:100% (5/5)。

GPT-4在專業考試中分數名列前茅
3 GPT-4的技術特征和不足
與ChatGPT類似,GPT-4 也是一種基於 Transformer 的大模型,支持多國語言,經過預訓練可以預測或自動生成文本。
OpenAI表示,對GPT-4而言,訓練後的對齊《Alignment》是提高性能和改善體驗的關鍵。從技術上看,人類反饋強化學習《RLHF》微調仍然是GPT-4的要點。考慮到LLM領域的競爭格局和 GPT-4 等大型模型的安全隱患,OpenAI暫時還未公佈GPT-4的模型架構、模型大小、訓練技術。

GPT-4解讀圖片《原文為英文,由作者翻譯為中文》
相對於GPT-3.5和其他大語言模型,GPT-4在復雜任務上表現出更可靠、更有創意,並且能夠處理更細微的指示的關鍵特征。
GPT-4 可以接受文本和圖像提示,並允許用戶指定任何視覺或語言任務。例如,GPT-4可以在給定由分散的文本和圖像組成的輸入的情況下反饋文本輸出《例如自然語言、代碼等》。在帶有文本和照片的文檔、圖表或屏幕截圖方面,GPT-4 也駕輕就熟。此外,GPT-4包括few-shot和思維鏈提示。對於公眾來說,圖像輸入仍然是僅供內部研究預覽,並不公開。而且,這次GPT-4直接整合入Bing搜索引擎之中。《Google壓力有點大啊》

GPT-4也有一些不足,例如仍然會一本正經的胡說八道,上下文連續對話輪次有限,並且無法從經驗中學習。因此如果不對GPT-4的使用進行安全性限制,GPT-4可能會產生大量的認知偏差、虛假信息,甚至侵犯個人隱私。另外,由於數據集時效的原因,GPT-4缺乏對 2021年9 月之後的事件的了解。GPT-4有時會犯一些簡單的推理錯誤,也可能會像人類一樣在技術難題上出現錯誤,例如GPT-4可能在生成的代碼中引入安全漏洞。
相比ChatGPT,GPT明顯在解決數理問題上有所提升,都能解包含圖文的物理題了。《熊孩子的暑假作業有救了》

GPT-4解物理題
4 GPT-4的訓練信息
OpenAI表示,在過去2年的GPT-4的研發中,超算和訓練技術表現出至關重要的價值。《據稱是數百人搞2年》
OpenAI與Azure的超算團隊一起,共同設計了針對大模型訓練的超級計算機,為GPT-4的訓練提供了關鍵的算力支撐和研發加速。《微軟爹的鈔能力》 OpenAI在GPT-4技術報告中,甚至把Supercomputing lead和Infrastructure lead的排名放在了預訓練模型團隊的最前面。
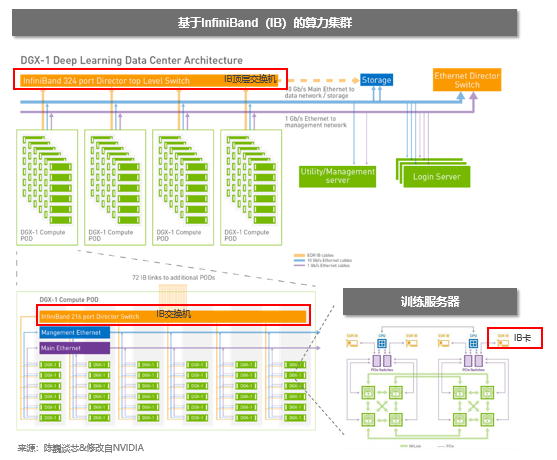
大模型算力集群架構
並且OpenAI的團隊從理論基礎層面進行了優化,改進了GPT-3.5的一些bug,使得GPT-4能夠以前所未有的進行穩定高速的訓練。這方面可以看出OpenAI團隊的數學和計算理論功底。
從技術報告描述的模型訓練過程來看,GPT-4的訓練與GPT-3.5類似。包括SFT的預訓練、基於RLHF的獎勵模型訓練和強化學習的PPO算法微調。與之前的GPT模型不同的是,OpenAI使用基於規則的獎勵模型 (RBRM) 在PPO 微調期間向 GPT-4 提供額外的獎勵信號。

GPT-4訓練流程《基於GPT-4技術報告繪制》

GPT-4訓練數據集《筆者預測》
GPT-4的訓練數據集是基於GPT-3和GPT-3.5的訓練數據集構建的,並在兩者基礎上增加了多模態數據集。GPT-4 的數據收集是由 Wojciech Zaremba《數據集團隊經理》和 Qiming Yuan《數據集采購和處理負責人》領導的一項艱巨任務。數據集貢獻來自一個由 30-50 名 OpenAI 員工組成的團隊,並另外從第三方網站雇傭了固定的50-100名標註員。
根據GPT-4的技術報告,可以分析GPT-4的多模態數據集包括圖表推理、物理考試、圖像理解、論文總結、漫畫圖文等不同類型。目前GPT-4的多模態算法還處於實驗中,並未對公眾開放。
5 GPT-4的安全性技術
OpenAI投入了大量資源來提高 GPT-4 的安全性和一致性。包括引入領域專家進行對抗性測試和紅隊測試,模型輔助的安全流水線以及安全指標的改進。OpenAI引入的領域安全專家達到了50多人,覆蓋AI一致性風險、網路安全、生物風險等領域。
與ChatGPT一樣,OpenAI使用強化學習和人類反饋 (RLHF) 來微調模型的行為,以產生更符合用戶意圖的響應。但當給定不安全的輸入時,模型可能會生成不良內容,例如提供有關犯罪的建議。另外,模型也可能對安全輸入變得過於謹慎,拒絕無害的請求。
GPT-4的安全流水線包括兩個主要部分:一組額外的安全相關 RLHF 訓練提示,以及基於規則的獎勵模型 (RBRM)。RBRM是一組zero-shot GPT-4 分類器。這些分類器在 RLHF 微調期間為 GPT-4 策略模型提供額外的獎勵信號,以正確的輸出行為為目標進行訓練,例如拒絕生成有害內容或不拒絕無害的請求。
技術報告地址:
作者簡介:陳巍 博士
存算一體/GPU架構和AI專家,高級職稱。中關村雲計算產業聯盟,中國光學工程學會專家,國際計算機學會《ACM》會員,中國計算機學會《CCF》專業會員。曾任AI企業首席科學家、存儲芯片大廠3D NAND設計負責人。
相關閱讀參考———————————
————————————————