ChatGLM-6B是清華大學知識工程和數據挖掘小組《Knowledge Engineering Group (KEG) & Data Mining at Tsinghua University》發佈的一個開源的對話機器人。根據官方介紹,這是一個千億參數規模的中英文語言模型。並且對中文做了優化。本次開源的版本是其60億參數的小規模版本,約60億參數,本地部署僅需要6GB顯存《INT4量化級別》。
ChatGLM-6B模型卡信息:https://www.datalearner.com/ai-models/pretrained-models/ChatGLM-6B
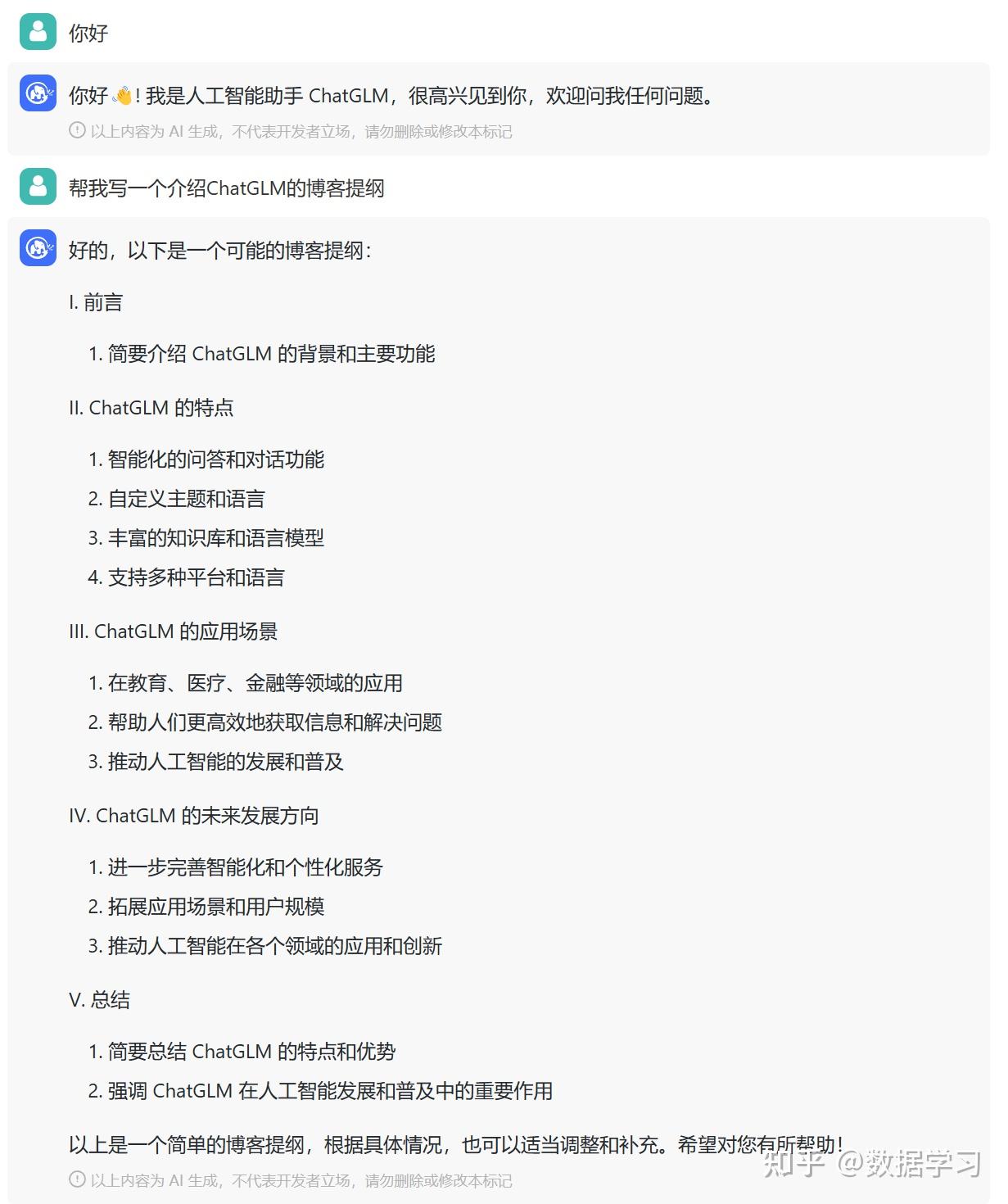
從目前的使用情況看,這個模型雖然不大,但也是與ChatGPT類似,做了針對對話的調優,使用體驗很好。
下圖是幾個對話實例:

該模型的基礎模型是GLM《 GLM: General Language Model Pretraining with Autoregressive Blank Infilling 》,是一個千億基座模型,目前僅接受內測邀請。
根據測試,ChatGLM-6B雖然參數很少,但是效果很好。對於硬件的需求也很低。
硬件需求:
量化等級最低GPU顯存FP16《無量化》13GBINT810GBINT46GB
ChatGLM-6B模型的具體安裝使用方法以及其它信息,請參考ChatGLM-6B模型卡內容: