ChatGPT詳解
詳解GPT字母中的縮寫
GPT,全稱Generative Pre-trained Transformer ,中文名可譯作生成式預訓練Transformer。
對三個英文進行解讀:
Generative生成式。GPT是一種單向的語言模型,也叫自回歸模型,既通過前面的文本來預測後面的詞。訓練時以預測能力為主,隻根據前文的信息來生成後文。與之對比的還有以google的Bert為代表的雙向語言模型,進行文本預測時會結合前文後文信息,以”完形填空”的方式進行文本預測。
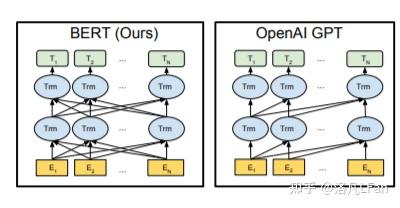
Pre-trained:預訓練讓模型學習到一些通用的特征和知識。預訓練的Bert通常是將訓練好的參數作為上遊模型提供給下遊任務進行微調,而GPT特別是以GPT3超大規模參數的模型則強調Few-shot《少樣本學習,給出N個上下文和完成結果的示例,然後給出一個上下文的最終示例,模型需要提供完成結果》,Zero-shot(零樣本學習,不需要給出示例,直接讓語言模型執行相應任務》能力,無需下遊微調(Fine-tuning)即可直接使用《如GPT-3,無需進行額外參數調整即可滿足各種任務需求》。
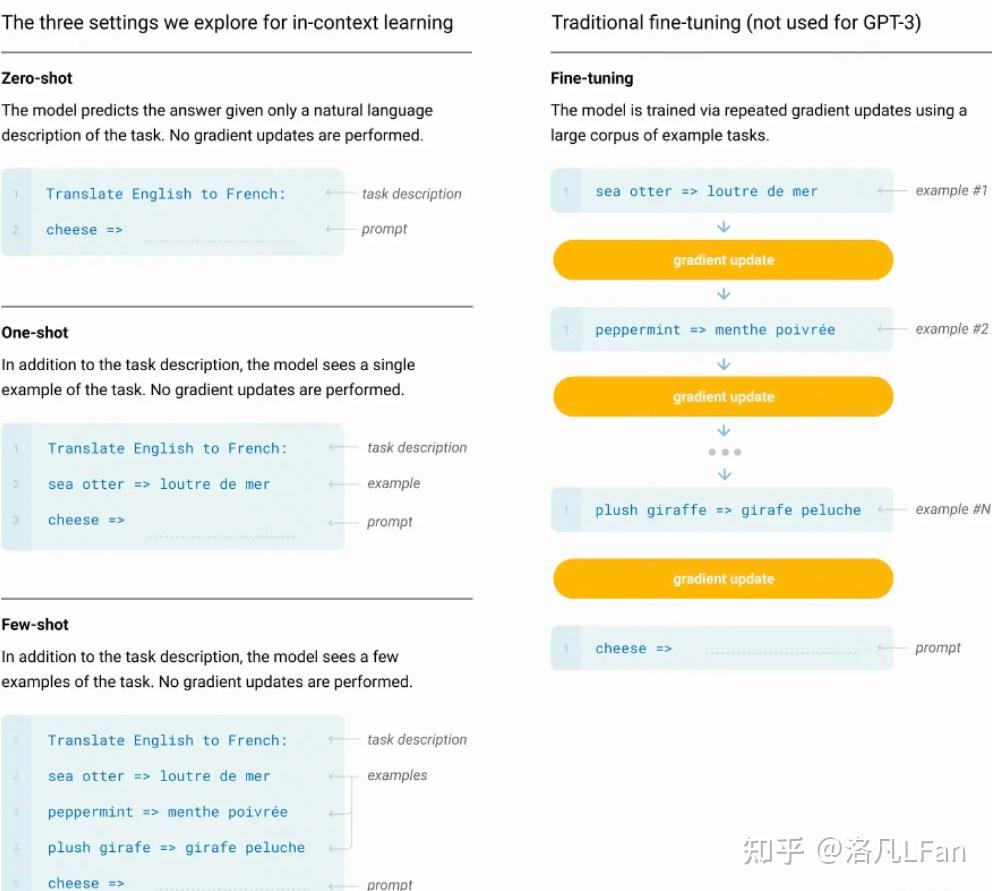
One-shot,單樣本學習,隻給出一個示例,模型即可以完成任務
Transformer:Transformer是一種基於編碼器-解碼器結構的神經網路模型,最初由Google在2017年提出,用於自然語言處理《NLP》領域。Transformer是一種基於自注意力機制《Self-attention Mechanism》的模型,可以在輸入序列中進行全局信息的交互和計算,從而獲得比傳統循環神經網路更好的長距離依賴建模能力。後文會介紹Transfomer以及自注意力相關機制。
基於生成式的語言模型
什麼是生成式?就是生成文本時,通過前面的單詞,來預測後面生成的內容。
最常見的生成式可以追溯到日常使用搜索引擎中的下拉提示框

而現如今的文本生成已經實現了通過文字描述的大部分需求《但其援引的文獻真實性有待考證,以及個人能否將該需求描述出來》

ChatGPT的十一大功能及應用場景
文字應當是我們獲取知識最高效、記憶最長久的手段,相較於一閃而過的視頻和音頻。那麼,作為文字生成式的AI,他的使用前景是非常廣闊的。
已知的功能及應用場景:
1、寫報告:報告開頭、報告總結、研究報告、提出反方觀點
2、資料整理:摘錄重點、采集資料、內容總結
3、履歷與自傳:精簡經歷、定制化履歷
4、程序開發:解BUG、寫代碼、寫測試、代碼調優
5、知識學習:簡易教學、深度教學、教學和測驗、概念說明
6、英文學習:翻譯、英文語法校驗、作文修改
7、工作生產力:回應email
8、寫作幫手:撰寫標題、撰寫大綱、撰寫文章
9、日常生活:提供食譜、活動企劃清單、提供點子、旅遊計劃、食譜生成
10、有趣好玩:寫歌詞、故事、寫RAP
11、角色扮演:擔任導遊、面試官、綜合情境
Transformer模型詳解
2017年6月,google大腦團隊《Google Brain》在神經信息處理系統大會《NeurIPS,該會議為機器學習與人工智能領域的頂級學術會議》發表了一篇名為『Attention is all you need』《自我注意力是你所需要的全部》的論文。作者在文中首次提出了基於自我注意力機制《Self-attention》的變換器《Transformer》模型,並首次將其用於理解人類的語言,即自然語言處理。該模型替代了以往使用RNN《循環神經網路,Recurrent Neural Network》來處理自然語言問題帶來的前後文較長時產生遺忘、嚴重依賴順序計算而導致並行計算效率不高等問題。
而該Transformer模型的優點,就在於能夠同時並行進行數據計算和模型訓練,訓練時長更短,並且訓練得出的模型可用語法解釋,也就是模型具有可解釋性。
Transformer模型結構
Transformer由若幹個編碼器和解碼器組成,如下圖所示:

可以看到 Transformer 由 Encoder 和 Decoder 兩個部分組成,Encoder 和 Decoder 都包含 6 個 block。
我們將Encoder和Decoder拆開,可以看到完整的結構,如下圖所示:
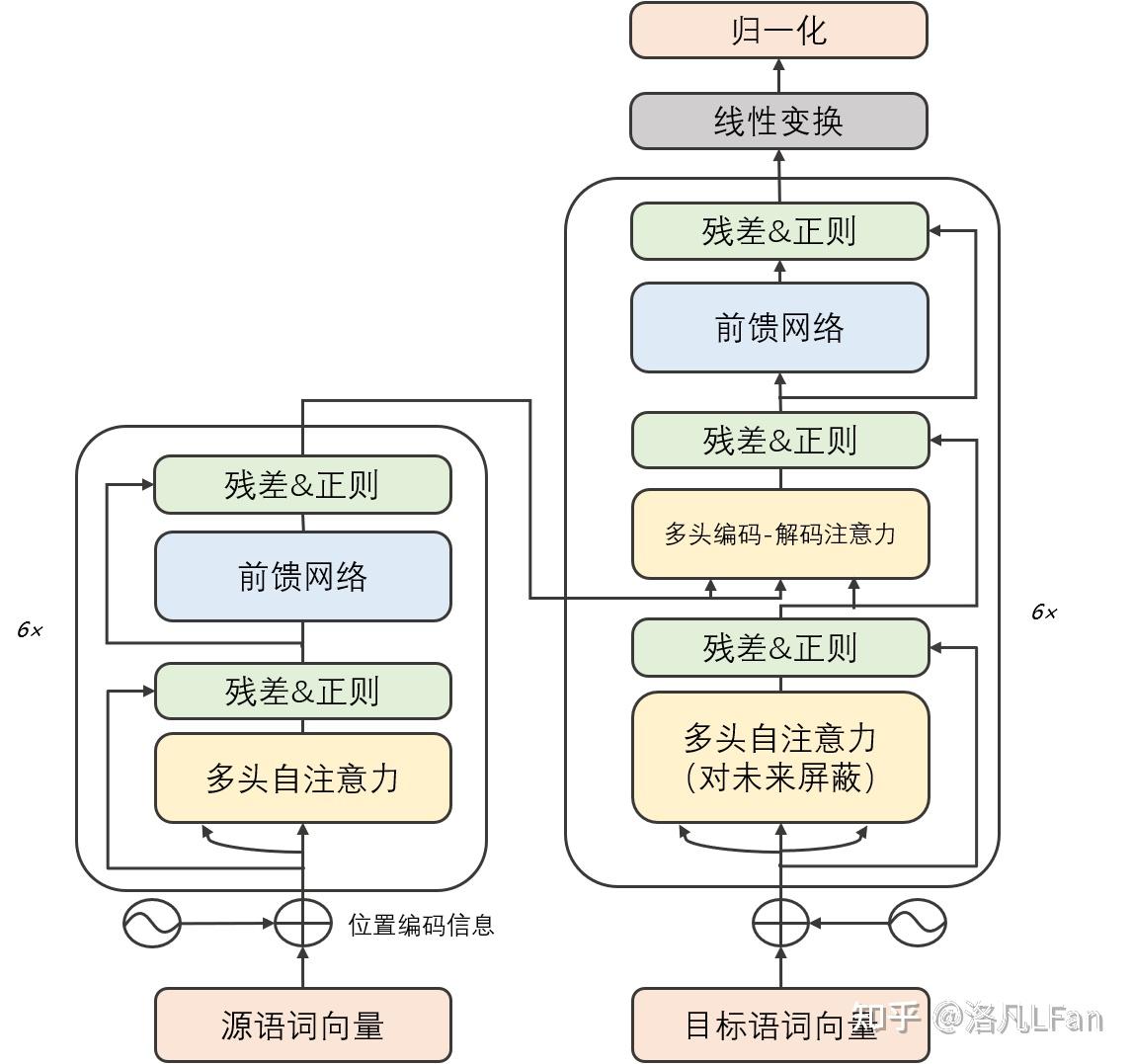
Transformer 的工作流程
第一步:獲取輸入句子的每一個單詞的表示向量 X,X由單詞的 Embedding 和單詞位置的 Embedding 相加得到。

Transformer 的輸入表示
第二步:將得到的單詞表示向量矩陣 (如上圖所示,每一行是一個單詞的表示 x) 傳入 Encoder 中,經過 6 個 Encoder block 後可以得到句子所有單詞的編碼信息矩陣 C,如下圖。單詞向量矩陣用 X_{n\times d} 表示, n 是句子中單詞個數,d 是表示向量的維度 (論文中 d=512)。每一個 Encoder block 輸出的矩陣維度與輸入完全一致。

Transformer Encoder 編碼句子信息
第三步:將 Encoder 輸出的編碼信息矩陣 C傳遞到 Decoder 中,Decoder 依次會根據當前翻譯過的單詞 1~ i 翻譯下一個單詞 i+1,如下圖所示。在使用的過程中,翻譯到單詞 i+1 的時候需要通過 Mask (掩蓋) 操作遮蓋住 i+1 之後的單詞。

Transofrmer Decoder 預測
上圖 Decoder 接收了 Encoder 的編碼矩陣 C,然後首先輸入一個翻譯開始符 “<Begin>”,預測第一個單詞 “I”;然後輸入翻譯開始符 “<Begin>” 和單詞 “I”,預測單詞 “have”,以此類推。
這裡面向的是普適大眾群體,就不細談各個部分的細節。
如果有興趣深入了解其數學公式及算法實現,可以參考Transformer 模型詳解
如果還有更進一步興趣,進行代碼復現,可以參考Transformer註釋及實現The Annotated Transformer
自我注意力機制《Self-Attention》
在講Self-Attention之前,先講廣義上的Attention機制。
Attention機制可以用一句話概括就是,分配權重系數。
Attention函數的本質可以被描述為一個查詢《query》到一系列《鍵key-值value》對的映射。

Attention Value= QK^{T}V
如果序列中每一個元素都以(K,V)形式存儲,那麼Attention則通過計算Q和K的相似度來完成尋址。Q和K計算出來的相似度反映了取出來的V值的重要程度,即權重,然後加權求和就得到了Attention值。
Attention的精髓便在於,某一個輸出並不需要所有encoder信息,而是隻需要部分信息。
舉個例子來說:假如我們正在做機器翻譯,將『I am a student』翻譯成中文『我是一個學生』。在輸出『學生』時,我們用到了『我』『是』『一個』以及encoder的輸出。但事實上,我們或許並不需要『I am a 』這些無關緊要的信息,而僅僅隻需要『student』這個詞的信息就可以輸出『學生』《或者說『I am a』這些信息沒有『student』重要》。這個時候就需要用到attention機制來分別為『I』、『am』、『a』、『student』賦一個權值了。例如分別給『I am a』賦值為0.1,給『student』賦值剩下的0.7,顯然這時student的重要性就體現出來了。
而Self Attention機制在KQV模型中的特殊點在於Q=K=V,這也是為什麼取名Self Attention,因為其是文本和文本自己求相似度再和文本本身相乘計算得來。
Attention是輸入對輸出的權重,而Self-Attention則是自己對自己的權重,之所以這樣做,是為了充分考慮句子之間不同詞語之間的語義及語法聯系。例如『I am a student』分別是對am的權重和對student的權重。用白話來講就是,當輸入一個句子時,裡面的每個詞都要和該句子中的所有詞進行Attention計算。
如果想要了解詳細的數學公式的原理實現,可以參考Tensor2Tensor Transformers New Deep Models for NLP
參考
- Attention Is All You Need
- Transformer 模型詳解
- The Annotated Transformer
- Tensor2Tensor Transformers New Deep Models for NLP
本文轉載自:知乎, 作者:洛凡LFan