2023-01-18 更新:
我們的paper:How Close is ChatGPT to Human Experts? Comparison Corpus,Evaluation,and Detection,現已可在Arxiv上訪問!
How Close is ChatGPT to Human Experts? Comparison Corpus,Evaluation,and Detection
數據集、模型均已開源,請大家關注我們的項目 :GitHub – Hello-SimpleAI/chatgpt-comparison-detection: Human ChatGPT Comparison Corpus (HC3),Detectors,and more!
我們提出了首個「人類-ChatGPT 問答對比語料集」,也是最早開發ChatGPT檢測器的團隊,過去四十天我們熬了很多夜,除了艱難的數據收集過程,還做了大量人工測評《圖靈測試,有用性測試等》、語言學分析以及各種類型的檢測器的開發。作為一個純純的中國學生團隊《非清北復交,甚至一開始素不相識》,我們一開始是覺得我們難以完成最初的設想的,但經過40天的奮戰,我們最初想做的基本都做到了,所以容許我為我們團隊感到自豪!感謝並肩作戰的好兄弟們!❤️❤️
—下面是原文—
那一夜…
- 2022年11月30號,OpenAI推出了ChatGPT,給NLP屆乃至各行各業的人帶來了巨大的驚喜和驚嚇[1];
- 2022年12月5號,由於受到ChatGPT的沖擊,Stack Overflow宣佈禁止用戶在平臺上發佈由ChatGPT生成的內容[2];
- 2022年12月8號,我夜不能寐,作為一個普普通通NLP研究者,被ChatGPT沖擊到自我懷疑,不斷反問自己在ChatGPT時代還能做些什麼研究。思來想去,我覺得在ChatGPT如此強大的情況下,我們非常需要一個ChatGPT檢測器,來判斷一段內容是否是ChatGPT生成的……
當晚我很晚才睡著,但是第二天一大早就醒了,興沖沖得跟幾個好友討論了這個事兒,經過一番討論,我們覺得這是個有價值的事兒,值得一做!接著我們在一個更大的群裡《孤勇AI研究者群hhh》,對這個話題展開了熱烈討論。當天晚上,我們便組建了一個由海內外6所高校或企業的博士生/工程師組成的8人團隊,為了一個共同的目標:
『 開發一套ChatGPT檢測工具,同時收集第一手寶貴的人類-ChatGPT對比數據集,來助力相關學術研究。
這一天是2022年12月9日,是ChatGPT推出的第10天。我們一幫普普通通的國內AI孤勇者們,就這樣踏上了一段充滿未知和挑戰的旅程。

在我們立項之後,也有有業界大佬提出類似的想法,例如一流科技創始人袁老師 @袁進輝 12月11日提到『我覺得一個迫在眉睫的需要研究的問題是,怎麼區分真實由人類生成的文本和chatGPT生成的文本?』

另外,12月21日,清華大學也開始招募志願者來收集ChatGPT的中文數據;而在國外,根據最近的新聞,普林斯頓大學也有團隊在做類似的事情,並於1月3日提出了一個demo (即最近很火的GPTZero)。
相比之下,我們可能是最早開始這方面研究的團隊了,但是一直很低調而忙碌地在收集數據、分析、訓練模型….《其實應該學習人家普林斯頓大學團隊,不管東西做了多少,先放出一個Demo….哎,少不更事啊!》
雖然風頭被搶了,但我們團隊一開始的初衷就不是蹭熱度,而是為社區做出一些真正的貢獻,ChatGPT檢測器隻是我們計劃的一部分,我們計劃:
- 收集一批有價值的人類和 ChatGPT 對比的中英雙語問答語料,這對於我們研究人類和大型語言模型《LLM》很重要,可以幫助我們研究LLM的特點、跟人類的差距、未來LLM改進的方向;
- 對大量的人機對比語料進行細致的分析,並進行多方面的人工評測,探究人類和ChatGPT分別具有什麼有趣的潛在的模式。這些探索將有助於思考LLM未來應去往何方;
- 最後,基於對比數據集以及語料分析,開發應對不同場景的一系列檢測模型,這些模型可幫助普通用戶和UGC平臺來**識別、監管AIGC (AI Generated Content)**。
項目進展
今天,距離我們立項,已經過去了大約一個月。
一個月,我們的私有倉庫進行了 166 次 commits,大家基本每天都在為之奮鬥:

今天,我們已經收集了中英文的 3-4 萬個問題和近 10 萬條「人類-ChatGPT 對比」回答語料,涵蓋了開放域、計算機科學、金融、醫療、法律、心理等多個領域。這批語料集從各個領域,反映了人類專家和 ChatGPT 在面對同一個問題時會有怎麼不同的回答;
我們對這批對比語料進行了大量的特征分析,發現了很多有趣的結論,相關的人工測評也正在緊鑼密鼓的進行,基於這個語料庫和相關分析,我們開發了三種使用不同算法、針對不同場景的 ChatGPT 檢測模型《都支持中文和英文,已經上線 Hugging Face Spaces》:

我們近期的計劃如下:
EventsDatesProject Launch / 項目啟動2022-12-09 ✅Comparison Data Collection / 對比數據收集2022-12-11 to Now ♀️Release ChatGPT Detector (Demo) / 檢測器 Demo 發佈2023-01-11 ✅Models Release / 模型開源Coming in a week Comparison Corpus Release / 語料集開源Coming in a week Research Paper / 研究論文發佈Coming in a week ……
歡迎大家關注我們的項目主頁:https://github.com/Hello-SimpleAI/chatgpt-comparison-detection
我們將於大約一周內開源代碼、模型和語料集,希望得到大家的寶貴反饋!
ChatGPT 檢測器展示:
下面,我們使用我們的檢測器,對多個平臺的內容以及ChatGPT相應的生成內容,進行檢測,包括
英文:
- Wikipedia概念解釋
- Quora開放問答
中文:
- 百度百科概念解釋
- 知乎開放問答
Wikipedia
GPT系列模型都在Wikipedia語料上進行了充分的訓練,這導致GPT系列模型會生成跟WIkipedia風格十分類似的文本,因此Wikipedia語料十分考驗檢測器的能力,下面我們隨機找一個概念,分別檢測人類專家的解釋和ChatGPT的解釋:
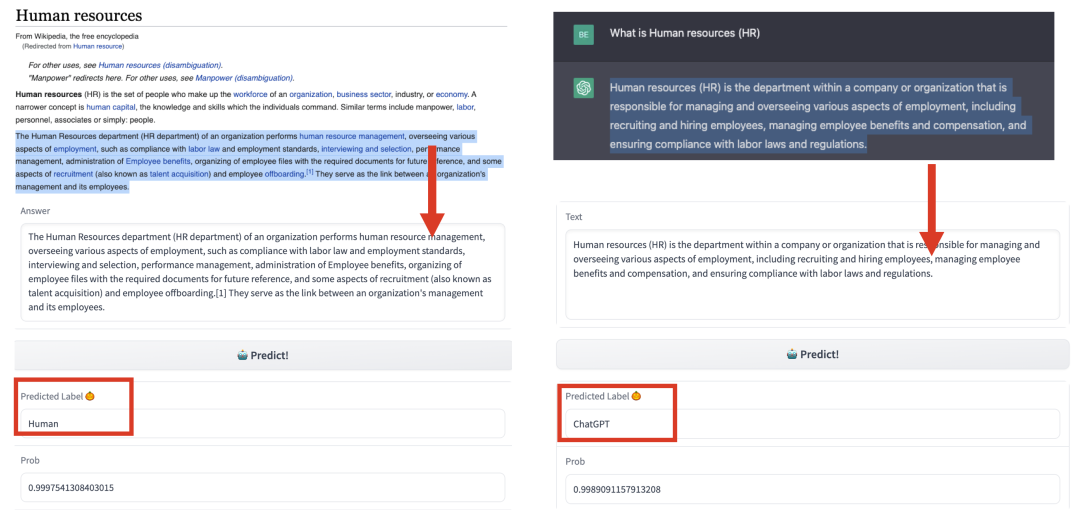
預測正確!《我們同時測了GPTZero,發現其預測錯誤。GPTZero主要使用文本困惑度以及句子間的困惑度變化來進行預測,一般人類的句子間困惑度差異會較大,而AI生成的內容則較小,而對於WIkipedia這種十分規范的文體,可能句子間的困惑度差異也較小,因此可能導致GPTZero判斷錯誤》
Quora

百度百科

知乎
知乎上,我們選取了問題『如何評價OpenAI的超級對話模型ChatGPT』,並測試了周博磊老師 @周博磊 的回答和ChatGPT自己的回答:

最後,希望大家關注我們項目:

我們也邀請廣大朋友一起來調戲我們的檢測器,如果能為我們提供一下預測錯誤的Bad Cases,那就太感激了!
我們的開源代碼、模型和語料集,將會和我們的研究論文一並在近期公佈,屆時再進一步跟朋友們進行交流。
鑒於 OpenAI 的『不Open』,以及 AIGC 對當下學界的沖擊和社會的潛在風險,我們希望能和更多志同道合的朋友,一起為開放的學術研究做貢獻!❤️❤️
相關鏈接:
[1] ChatGPT: https://openai.com/blog/chatgpt/ [2] Stack Overflow禁用 ChatGPT: https://meta.stackoverflow.com/questions/421831/temporary-policy-chatgpt-is-banned [3]GPTZero: http://gptzero.me/