免責聲明
本人非AI背景,對NLP的理解非常有限,因此無法保證本文中所有內容都是正確的。筆者非常歡迎大家能夠指出文中的錯誤。
此外,文中配圖均來自網路,版權歸原作者所有,如果不希望自己的圖被使用的話可聯系刪除。
2022/12/27 第一次修訂
本文的原始版本缺失了GPT3以及上下文學習(In-Context Learning)的相關內容。隨著相關知識的學習,筆者意識到了這部分內容對理解ChatGPT是非常重要的,因此在本次修訂加入『上下文學習』的內容,並更新了『遷移學習』和『強化學習』相對應的描述。
前言
最近一周多的時間,只要不是生活在火星,喜歡技術的同學一定都被OpenAI的ChatGPT給刷屏了。 ChatGPT與以往的公開提供服務的對話機器人相比,性能有了顯著的提高。它可以相對可靠地提供一些日常對話、知識獲取的功能,也可以它根據人類提供的需求幫忙寫文檔、寫代碼,甚至可以修改文本中的各類錯誤或者代碼中的Bug。我相信很多非AI圈的同學肯定會有一種『為什麼AI突然變得這麼強?『的感受。這篇文章的目的也是為了回答這個問題。在開始之前,我覺得有必要先表達一下我自己的看法:NLP技術發生跨越式發展的標志並不是ChatGPT本身,而應該是2017年-2020年間相繼被提出的Transformer[1]和GPT系列[2][6]。
ChatGPT是Transformer和GPT等相關技術發展的集大成者。總體來說,ChatGPT的性能卓越的主要原因可以概括為三點:
我們接下來將會針對這三點進行探討。
機器學習模型
在步入正題之前,我們可以先梳理一下NLP發展的歷史。
基於文法的模型
這個階段,大家處理自然語言的主要思路就是利用語言學家的智慧嘗試總結出一套自然語言文法,並編寫出基於規則的處理算法進行自然語言處理。這個方法是不是乍聽起來還行?其實我們熟悉的編譯器也是通過這種方法將高級語言編譯成機器語言的。可惜的是,自然語言是極其復雜的,基本上不太可能編寫出一個完備的語法來處理所有的情況,所以這套方法一般隻能處理自然語言一個子集,距離通用的自然語言處理還是差很遠。
基於統計的模型
在這個階段,大家開始嘗試通過對大量已存在的自然語言文本《我們稱之為語料庫》進行統計,來試圖得到一個基於統計的語言模型。比如通過統計,肯定可以確定『吃』後面接『飯』的概率肯定高於接其他詞如『牛』的概率,即P(飯|吃)>P(牛|吃)。
雖然這個階段有很多模型被使用,但是本質上,都是對語料庫中的語料進行統計,並得出一個概率模型。一般來說,用途不同,概率模型也不一樣。不過,為了行文方便,我們接下來統一以最常見的語言模型為例,即建模『一個上下文後面接某一個詞的概率『。剛才說的一個詞後面接另一個詞的概率其實就是一元語言模型。
模型的表達能力
在這裡,我們很適合插播一下模型表達能力這個概念。

模型表達能力簡單來說就是模型建模數據的能力,比如上文中的一元語言模型就無法建模『牛吃草』和『我吃飯』的區別,因為它建模的本質統計一個詞後面跟另一個詞的概率,在計算是選『草』還是選『飯』的時候,是根據『吃』這個詞來的,而『牛』和『我』這個上下文對於一元語言模型已經丟失。你用再多的數據讓一元語言模型學習,它也學不到這個牛跟草的關系。
模型參數數量
有人說,既然如此,為啥我們不基於更多的上下文來計算下一個詞的概率,而僅僅基於前一個詞呢?OK,這個其實就是所謂的n元語言模型。總體來說,n越大,模型參數越多,表達能力越強。當然訓練模型所需要的數據量越大《顯然嘛,因為需要統計的概率的數量變多了》。
模型結構
然而,模型表達能力還有另一個制約因素,那就是模型本身的結構。對於基於統計的n元語言模型來說,它隻是簡單地統計一個詞出現在一些詞後面的概率,並不理解其中的各類文法、詞法關系,那它還是無法建模一些復雜的語句。比如,『我白天一直在打遊戲』和『我在天黑之前一直在玩遊戲『兩者語義很相似,但是基於統計的模型卻無法理解兩者的相似性。因此,就算你把海量的數據喂給基於統計的模型,它也不可能學到ChatGPT這種程度。
基於神經網路的模型
上文提到,統計語言模型的主要缺點是無法理解語言的深層次結構。曾有一段時間,科學家們嘗試將基於文法的模型和基於統計的模型相結合。不過很快,風頭就被神經網路搶了過去。
RNN & LSTM
剛開始,流行的神經網路語言模型主要是循環神經網路(RNN)以及它的改良版本LSTM。

RNN的主要結構如下, x是輸入,o是輸出,s是狀態。

如果RNN作為語言模型的話,那x可以作為順序輸入進去的詞匯,而o就可以作為輸出的詞匯,而s就是通過x計算o的過程中生成的狀態變量,這個狀態變量可以理解為上下文,是對計算當前詞匯時前文所有出現過的所有單詞的濃縮並在一次次的計算中不斷迭代更新。這也是為啥RNN可以建模詞與詞關系的根本原理。
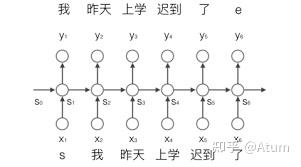
與簡單的基於統計的模型相比,循環神經網路的主要亮點就是能夠對一段文字中不同詞之間的關系進行建模,這種能力在一定程度上解決了基於統計的模型無法理解深層次的問題。

Attention Mechanisms
在更進一步之前,我們不得不提一下注意力《Attention》機制。

這個機制主要針對RNN語言模型中狀態S作為上下文這一機制進行改進。。在RNN中計算當前詞後的狀態Si主要是通過計算上一個詞時的狀態Si-1迭代出來的。它的主要缺點就是它假設了距離較近的詞匯之間的關系更密切。但是我們都知道,在自然語言中,這一假設並不是一直成立的。引入Attention之後,計算第i個詞後的狀態從單純的Si變成了S0,S1…Si的組合,而具體『如何組合』,即哪個狀態比較重要,也是通過數據擬合出來的。在這樣的情況下,模型的表達能力又得到了進一步的提高,它可以理解一些距離較遠但是又非常密切的詞匯之間的關系,比如說代詞和被指代的名詞之間的關系。

Transformer
接下來,我們終於可以祭出之前提過的NLP跨越式發展的標志之一,Transformer的提出!
其實在有了Attention之後,Transformer的提出已經是順理成章了。Transformer的主要貢獻在於1. 將Multi-Head Self-Attention直接內建到網路中。所謂Multi-Head Self-Attention其實就是多套並行的Self-Attention,可以用於建模的詞與詞之間的多類不同地關系。
2. 利用專用位置編碼來替代之前RNN用輸入順序作為次序,使得並行計算成為了可能。

舉一個形象但不準確的例子,對於句子I often play skating board which is my favorite sport. 如果使用Multi-Head Self-Attention,那就可以有一套Attention專門用來建模play和skating board的謂賓關系,有一套Attention用來建模skating board與favorite的修飾關系。從而使得模型的表達能力又得到了提高。

ChatGPT所依賴GPT3.5語言模型的的底層正是Transformer。
訓練數據
OK,我們現在有一個名為Transformer模型了,這個模型通過Multi-head Self-Attention,使得建立詞與詞之間的復雜關系成為了可能。因此可以說是一個表達力很強的語言模型了。然而,單有語言模型沒有數據就是巧婦難為無米之炊。
GPT-3.5的相關數據並未被公開。我們就隻說說它的上一代GPT-3。GPT-3整個神經網路就已經有1750億個參數了。這不難理解,想一想Attention憑什麼確定在當前上下文下哪些詞比較重要?而網路又怎樣通過Attention和輸入生成輸出?這些都是由模型裡面的參數決定的。這也是為啥模型結構一樣的情況下參數越多表達能力越強。那這些模型的參數怎麼拿到?從數據中學習!其實大多數所謂的神經網路的學習就是在學參數。
好家夥,要訓練1750億個參數的神經網路要喂多少數據呢?這麼多!(from wikipedia)
Dataset# TokensWeight in Training MixCommon Crawl410 billion60%WebText219 billion22%Books112 billion8%Books255 billion8%Wikipedia3 billion3%
可以預想的是,表達能力如此之強的模型,在喂入萬億級的數據之後,其對語言本身的理解已經開始接近人類了。比如它處理句子的時候,會通過訓練Attention參數理解到句子中哪些詞之間存在關系的?哪些詞和哪些詞之間是同義的?等一系列比較深度的語言問題。
這還隻是2020年的GPT-3。如今已經2022年了,相信GPT-3.5的模型表達能力比GPT-3又有相當大地提升。
訓練方法
監督學習 vs 無監督學習
簡單來說,監督學習就是在『有答案』的數據集上學習。如果我們要用監督學習(supervised learning)訓練一個中文到英文的機器翻譯模型,我們就需要有中文以及其對應的英文。整個訓練過程就是不斷地將中文送入到模型中,模型會給出一個英文的輸出,這個時候我們對比一下英文的輸出與標準答案的差距遠不遠《Measured by Loss Function》,如果差距比較大,那我們就調整模型參數。這也成為早期針對機器翻譯模型的主要訓練方法。

遷移學習
然而,『有答案』的數據終究是有限的。這也是限制之前很多自然語言學習的模型設計復雜度的原因。不是不想提高模型的表達能力,而是提上去之後,參數太多,我們沒有足量的『有答案』的數據來訓練這個模型。
2018年,另一個我認為NLP跨越式發展的標志來了,那就是GPT的提出。

GPT的主要貢獻在於,它提出了自然語言的一種新的訓練范式。即現通過海量的數據的無監督學習來訓練一個語言模型。正如我們之前提到過的,所謂語言模型即是在一個上下文中預測下一個詞,這個顯然是不需要帶有標註的數據的,現有的任何語料都可以作為訓練數據的。由於GPT的底層借用了表達能力很強的Transformer,互聯網經過長時間的發展,海量的無標記的自然語言數據也並不再是稀缺的事物。導致了訓練出來的模型其實對語言有了相當深入地理解。因此模型的最後一層通常也被稱為contextual emebedding。這個時候,如果你想讓這個語言模型能夠做文本摘要,你隻需要在模型的最後一層接一個全連接層,並用少量的數據做監督學習,即可以讓他學會文本摘要。這個過程也被稱為微調(fine-tune)。它是一種遷移學習(Transfer Learning)。
上下文學習
2020年,Open AI發表論文[6]正式推出了GPT3。GPT3的主要貢獻在於提出了大模型的上下文學習(In-Context Learning)的能力。所謂上下文學習,簡單來說就是通過向模型喂入一個提示(prompt),並選擇性的加入少量的任務的樣例,模型之後就可以利用Language Model的預測下一詞的形式自動生成相關任務的答案。

相比上一節提到的基於Fine-tune的遷移學習,上下文學習主要了提升了零樣本(Zero-shot)和少樣本(Few-shot)任務的能力。Fine-tune還是需要一定數量的帶標簽的數據做監督學習的,但上下文學習就隻需要及少量甚至完全不需要。這也為ChatGPT能夠應對各種各樣不同的問題提供了可能性。值得一提的是,上下文學習是隻有大模型(模型參數數量>40B)中才會出現的,因此學術界把這一類大模型才有的能力定義為突現能力(emergent ability)[7]
指令微調與強化學習
ChatGPT的目標是根據用戶輸入生成回復。在上下文學習的情況下,從輸入輸出的形式上來看,生成回答本身與語言模型是完全兼容的,都是根據一定的上下文生成一段文字。但是,生成回復和語言模型的內在目標卻是不一致的,語言模型致力於在一定上下文下預測可能性最大的下一個詞匯,而生成回復則是致力於生成一個人類認為比較滿意的回答。為了解決這個不一致性。ChatGPT在還使用了一種叫做reinforcement learning from human feedback (RLHF)的技術。
其總體原理如下圖所示,首先利用一系列問答對模型進行監督訓練《這個操作也叫監督指令微調)。在完成監督指令微調後,就開始利用強化學習對模型進行進一步的指令微調,具體地,首先在人類的幫助下訓練一個獎賞網路,這個獎賞網路具有對多個聊天回復好壞進行排序的能力。接著,利用這個獎賞網路,進一步通過強化學習(reinforcement learning)優化了聊天模型。該訓練方法的細節可以參考論文[3]

在這一通操作之後,ChatGPT就變成了我們現在看到的這樣子。
其他
至此,我們基本上就已經能明白為什麼ChatGPT這麼強了,但是我相信很多同學肯定會表示『就這?我不信,它都會改bug了,給他一段代碼他都知道代碼是幹什麼的了。』
Okay,我們可以首先解釋一下為什麼它可以做到修改代碼中的bug,根據OpenAI提供的信息 :"GPT-3.5 series is a series of models that was trained on a blend of text and code from before Q4 2021.",我們可以知道GPT-3.5中的訓練數據其實是包含了海量的代碼數據。所以說GPT-3.5對代碼的理解也是相當強的。從論文[4]可以看到,將代碼放入語言模型中進行訓練後,訓練出的語言模型已經可以做到代碼語義級的搜索。
而ChatGPT又是怎麼知道代碼的功能的呢?目前我還沒看到相關論文,不過可以參考一下OpenAI在GPT-3上做的代碼訓練的工作[5],大概就是將代碼和其功能docstring註釋放在一起做對比預訓練(contrastive pretrain),這樣可以讓語言模型理解代碼和其功能的關系。
總結
總之,ChatGPT並沒有那麼神秘,它本質上就是將海量的數據結合表達能力很強的Transformer模型結合,從而對自然語言進行了一個非常深度的建模。對於一個輸入的句子,ChatGPT是在這個模型參數的作用下生成一個回復。
有人會發現ChatGPT也經常會一本正經胡說八道,這也是這一類方法難以避免的弊端。因為它本質上隻是通過概率最大化不斷生成數據而已,而不是通過邏輯推理來生成回復。

向ChatGPT詢問比較嚴肅的技術問題也可能會得到不靠譜的回答。
