本篇文章是 OpenAI ChatGPT 系列文章的第五篇,在上一篇文章中,我們介紹了 GPT-1 的結構和代碼實現。
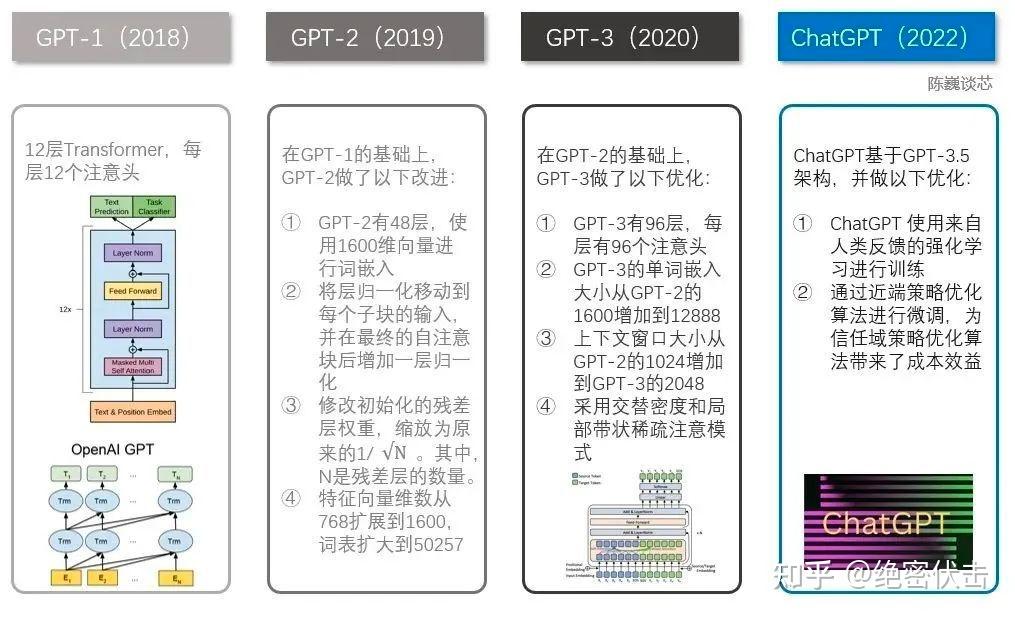
在介紹 GPT-2 之前,先讓 ChatGPT 幫我們回答下 GPT-2 和 GPT-1 的區別,如下圖所示。
:十分鐘讀懂 GPT-2。")
可以看到,GPT-2 相比 GPT-1,模型參數顯著增加,這個數字是怎麼得到的?計算方法如下:
N_{params} = N_{embedding} + L \times N_{self-attention} + L \times N_{feedforward} \times h + N_{decoder}\tag1 其中, N_{embedding} 表示 Embedding 層的參數數量, L 表示輸入序列的長度, N_{self-attention} 表示一個注意力頭的參數數量, N_{feedforward} 表示前饋神經網路的參數數量, h 表示多頭數, N_{decoder} 表示解碼器層的參數數量。
以計算 GPT-2 為例,GPT-2 的超參數如下:
- 序列長度 L=1024
- Embedding 層詞嵌入維度 d_{model}=1600
- 多頭數 h=25
- 前饋神經網路中間層維度 d_{ff}=6400
- 解碼器層數 num_layers = 48
- 詞匯表大小 vocab_size = 50257
根據上述參數,可以計算出 GPT-2 模型的總參數數量:
N_{embedding}=\text{vocab_size} \times \text{embedding_dim}=50257 \times 1600 = 80,411,200
N_{self-attention}=h\times(d_{model}\times d_{model} + d_{model}\times L + L \times d_{model})=25\times(1600\times 1600+1600\times 1024+1024\times 1600)=424,000,000
N_{feedforward}=d_{model}\times d_{ff}+d_{ff}\times d_{model}=1600\times 6400+6400\times 1600=16,384,000
N_{decoder}=(d_{model}\times \text{vocab_size})\times \text{num_layers}=1600\times 50257\times 48=3,863,644,160
因此,GPT-2 模型的總參數數量為:
N_{params}=N_{embedding} + L \times N_{self-attention} + L \times N_{feedforward} \times h + N_{decoder} = 80,411,200 + 1024 \times 424,000,000 + 1024 \times 16,384,000 \times 25 + 3,863,644,160 = 1,542,024,192\approx 1.54\text{B}
前言
GPT-2 是 OpenAI 在2019年提出的模型,發表在論文《Language Models are Unsupervised Multitask Learners》。
GPT-2 是 GPT-1 的改進版本,其模型結構和 GPT-1 相比幾乎沒有什麼變化,隻是讓模型變得更大更寬,並且取消了 Fine-tuning 的步驟。也就是說 GPT-2 采用了一階段的模型《預訓練》代替了二階段的模型《預訓練+微調》,並且在語言模型《文本摘要》等相關領取取得了不錯的效果。
GPT-1 是12層的 Transformer,BERT 最深是24層的 Transformer,GPT-2 則是48層,共有15億個參數。其訓練數據是一個稱為 WebText 的數據集,該數據集做了一些簡單的數據清洗,並且覆蓋領域十分廣闊,論文中指出規模大的模型必須要用更多的數據才能收斂,並且實驗結果表明目前模型仍然處於一個欠擬合的情況。在預訓練階段,GPT-2 采用了多任務的方式,不單單隻在一個任務上進行學習,而是多個,不同的任務是共享主體 Transformer 參數的,該方案是借鑒了之前微軟的 MT-DNN,這樣能進一步的提升模型的泛化能力,因此在即使沒有 Fine-turning 的情況下依舊有非常不錯的表現。
之前的NLP 模型大多數采用無監督的 Pre-training 和監督學習的 Fune-tuning,但這種方法的缺點是針對某特定任務需要不同類型標註好的訓練數據。
目前的數據集往往都是針對某一特定任務,如 QA 領域的 SQuAD 2.0,機器翻譯領域的 NIST04 和 WMT 2014 En-2-Fr 等。而正是因為數據集的單一導致系統缺乏泛化性。OpenAI 想通過盡可能地構建和利用足夠大的且多樣化的數據集,以保證最終的模型能夠應用於多個不同的 NLP 任務中。為此,OpenAI 專門爬了 Reddit 上 > 3 karma 的外鏈作為數據源,同時去除 wiki 數據,最終數據大小共 40G。由於 Reddit 上的數據會包括各個領域,所以既保證了數據質量、數量又保證了數據的多樣性。
此外,據研究表明語言模型有望完成某些特定的任務,如常識推理和情感分析等,所以 OpenAI 提出了去掉有監督的 Fine-tuning 階段,僅采用無監督 Pre-training 的語言模型來直接應用到下遊任務中。
OpenAI 通過 GPT-2 論證了這種方法的可行性,並證明了語言模型在相關領域具有很大的潛力。
1. GPT-2模型
自然語言處理任務,如問答、機器翻譯、閱讀理解和摘要,通常通過任務特定數據集上的監督學習來完成。OpenAI 證明,當語言模型在一個名為 WebText 的數百萬網頁的新數據集上進行訓練時,他們開始學習這些任務,而沒有任何明確的監督。當以文檔和問題為條件時,語言模型生成的答案在 CoQA 數據集上F1 達到0.55。語言模型的能力對於 zero-shot 任務至關重要,提高語言模型的能力可以顯著提高下遊任務的性能。GPT-2 在zero-shot 設置下,在8個測試數據集中有7個實現了SO他。
1.1 具體方法
GPT-2 的核心是一個語言模型,語言具有天然的順序性。和監督模型類似,語言模型是對序列的條件概率建模,通常可以表示為:
p\left( x \right)=\prod_{i=1}^{n}p\left( s_n|s_1,…,s_{n-1} \right)\tag2 可以泛化為: p\left( s_{n-k},…,s_n|s_1,…,s_{n-k-1} \right)\tag3
任何有監督的任務,都是在估計:
p\left( output|input \right)\tag4 通常我們會用特定的網路結構去給任務建模,但如果要做通用模型,它需要對下面的目標進行建模:
p\left( output|input,task \right)\tag5建模 p\left( output|input,task \right) 有很多方法,比如特定任務的 encoder 和 decoder,但是正如McCann所提出的,語言模型提供了一種靈活的方式來指定任務、輸入、輸出。比如對於機器翻譯任務,訓練樣本可以表示為序列《translate to french,english text,french text》;對於閱讀理解任務,訓練樣本可以表示為《answer the question,document,question,answer》。McCann等人證明,可以訓練單一模型 MQAN,使用這種格式的樣本,對不同的任務做 infer。
按照上面的方法,語言模型也能夠學習某些監督任務,並且不需要明確具體的監督符號。
相比於有監督的多任務學習,語言模型隻是不需要顯示地定義哪些字段是要預測的輸出,所以,實際上有監督的輸出隻是語言模型序列中的一個子集。
下面是 WebText 訓練集中的一個例子。
 訓練語料中包含了法譯英和英譯法
訓練語料中包含了法譯英和英譯法
在上面的例子中,我們在訓練語言模型時,語料中包含了法譯英的內容:
』Mentez mentez,il en restera toujours quelque chose,』 which translates as,』Lie lie and something will always remain.』
那麼在訓練完上面的文本後,語言模型自然地學習到了法語如何翻譯成英語。
因此監督學習通常隻是無監督學習的一個子集,所以無監督學習的全局最小也必定是監督學習的全局最小,目前的問題變為了無監督學習是否能收斂。
1.2 訓練數據集
大多數之前的工作都是針對單一文本領域訓練語言模型,如新聞文章、維基百科或小說。為此,OpenAI 從網上爬了一大堆語料,用來進行 LM 《Language Model》的 pre-train,數據集取名叫 WebText,有800萬左右的文檔,40G 的文本,並且還移除了 Wikipedia 的數據。
1.3 模型改動
在模型方面相對於 GPT -1 來說幾乎沒有什麼修改,隻是加入了兩個 Layer normalization,一個加在每個 sub-block 輸入的地方,另一個加在最後一個 self-attention block 的後面。
同時考慮到模型深度對殘差路徑的累積問題,GPT-2 采用了修正的初始化方法。在初始化時將殘差層的權重縮放到 \frac{1}{\sqrt{n}} 倍, n 為殘差層的數量。
此外,vocabulary 的大小擴展到了 50257,輸入的上下文大小從 512 擴展到了 1024,並且使用更大的 batch size《512》。
GPT-2 提供了四種不同規模的模型:
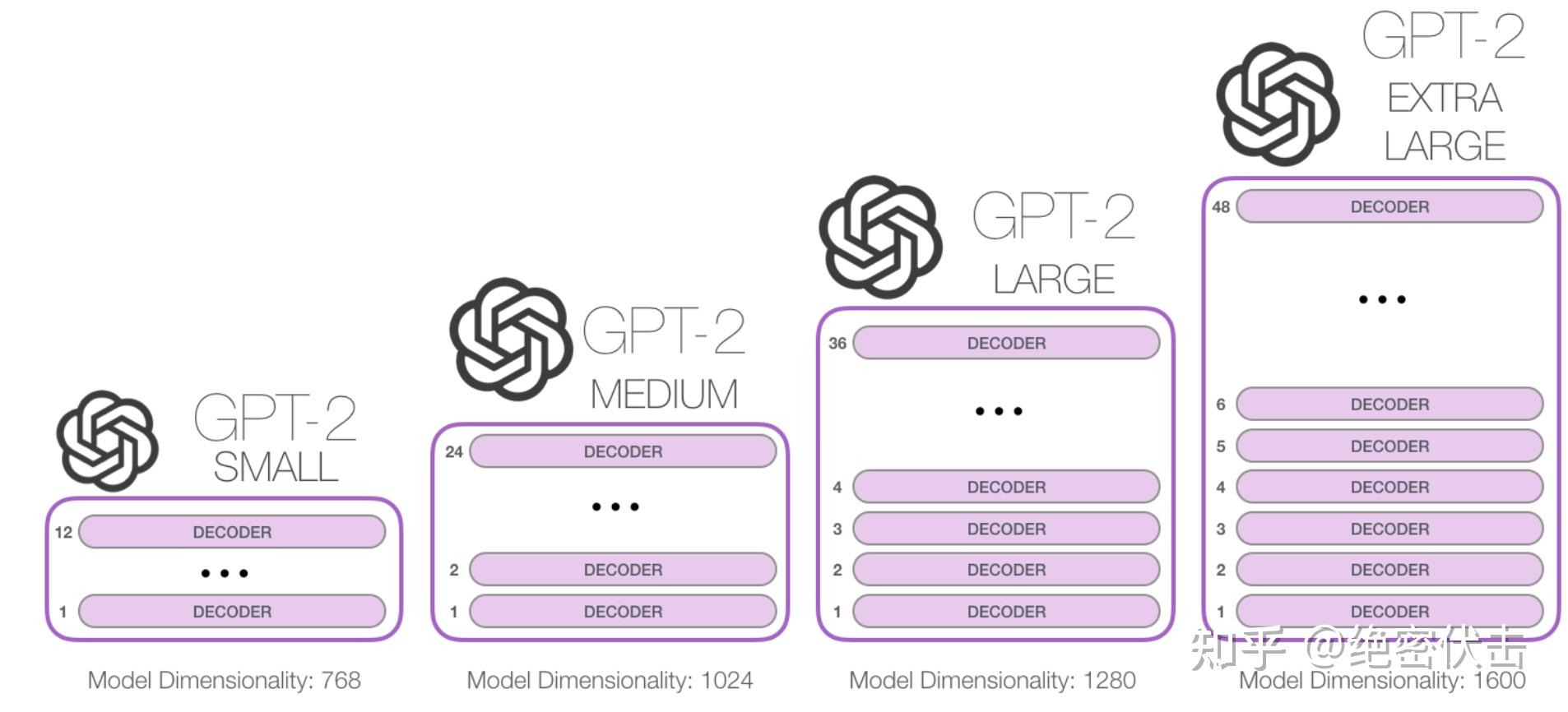
最大的 EXTRA LARGE 模型參數為1.5B《15億》。
2. 實驗結果
OpenAI 實現了幾種不同 size 模型,如下圖:
參數規模層數d_model117M12768345M241024762M3612801542M481600
OpenAI 直接將這個 pre-train 的模型,不用 fine-tuning 的跑了各個下遊的 NLP 任務,即 ZSL《Zero-Shot Learning》設定,結果如下:

這裡的 WikiText2、PTB、enwiki8、text8、WikiText103、1BW 是幾個測試語言模型的數據集;LAMBADA 是測試建模長句子能力的數據集,用於預測一句話的最後一個詞;CBT 是用於檢驗在不同類型的詞上 LM 的表現,主要是 Cloze 任務。
OpenAI 還測試了一些其他的任務,比如推理的任務 Winograd Schema Challange,結果如下:

最後,OpenAI 還給出了一個說明訓練難度的表格,用於說明這些任務的訓練集與測試集的文本重合度比較高,所以 SO他 的效果要打一些折扣,而 GPT-2 這裡用到的訓練數據則與測試集重合度較低,所以就更能說明 GPT-2 的提升效果。

總結
GPT-2 在 GPT 的基礎上采用單向語言模型,並舍去 Fine-tuning 階段,利用高質量多樣化的大文本數據訓練得到一個巨型模型,最終在語言模型相關的任務中取得了不錯的成績。
- 收集了一個大語料庫 WebText,即使像 GPT-2 這樣的大模型,也依然處於欠擬合的狀態
- 最大的 GPT-2 模型,有1.5B的參數量,用 ZSL 在很多任務上進行測試,發現有7/8的任務上都達到了 SO他
- 驗證了即使不做 Fine-tuning,大模型 + 大語料 + 多樣性數據在多個任務上也能取得不錯效果
參考
GPT2.0語言模型 Language Models are Unsupervised Multitask Learners
The Illustrated GPT-2 (Visualizing Transformer Language Models)
小虎AI玨爺:論文閱讀:語言模型是無監督的多任務學習者《GPT2 2019》
https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
李rumor:OpenAI GPT2原理解讀
騰訊雲開發者:ChatGPT深度解析:GPT家族進化史
數據科學人工智能:ChatGPT 算法原理