二、ChatGPT 使用技巧
2.1 提示工程
2.1.1 什麼是提示工程
從本小節開始,我們將 ChatGPT 視為一個具有一定智慧的『人類』,並將盡可能地將 ChatGPT 的行為與人類的行為進行類比。這樣才能更好地理解為什麼我們需要新增一些『概念』並設計一些『工具』,以幫助它更好地工作。
在近年來的自然語言處理發展過程中,『提示』一詞的含義發生了特別大的變化 [①]。在本書中,我們隻從使用者的角度來學習和研究提示。
在前面的 1.3.2 節中,我們講解了大型語言模型的一個神奇特性,即上下文學習。這個神奇的特性似乎賦予了大型語言模型快速『舉一反三』的能力。要想進行反三,必須先有好的舉一。就像如何向人類提出好的問題並給出好的示例一樣,這直接關系到回答的質量。提示工程的目標是如何更好地向 ChatGPT 提問、更好地描述和表達問題。
下面是提示工程較為官方的定義:
提示工程 是創建一組指令和文本,作為大型語言模型的輸入。通過這些指令和文本來引導大型語言模型完成我們的特定需求。好的提示工程和差的提示工程產生的結果有天壤之別。好的提示就像魔法咒語一樣,能讓大型語言模型產生神奇的效果。
遺憾的是,提示工程仍然是一門經驗性的學科,我們暫時沒有理論支持來指導我們如何設計出好的提示。因此,我們隻能通過不斷探索和積累經驗性的結論和方法來學習和發展提示工程。
2.1.2 提示的構成
提示的形式千差萬別,理論上我們可以設計出無數的提示。然而,本文將會介紹常見的提示方式,這些提示利用大型語言模型輔助我們完成特定的語言任務。
一般情況下,我們可以將提示分為 4 部分:
- 指令:表示你想讓大型語言模型完成的任務。
- 輸出要求:表示你對大型語言模型輸出的要求。
- 上下文背景:一些需要給到大型語言模型的外部信息,例如單樣本,少樣本學習中的示例。
- 問題:需要大型語言模型回答的具體問題。
實際上,上面的提示和對應的回答僅僅是單輪對話的例子。ChatGPT 本身是一個多輪對話系統。因此,作為用戶,在和 ChatGPT 進行多輪對話時,每次 ChatGPT 給出的最新回答都是基於你之前提出的問題以及你們的歷史對話內容。換句話說,利用多輪對話,我們可以進一步引導 ChatGPT,甚至糾正 ChatGPT 已經犯的錯誤。
單輪對話的提示:
。")
多輪對話的提示:

關於如何設計更具體的 Prompt,你可以參考這本書《The Art of Asking ChatGPT for High-Quality Answers》。書中提供了許多 Prompt 模板,可以供你使用。
2.2 工作記憶
2.2.1 什麼是工作記憶
請讀者不用筆和工具計算下面的算式:
4\times7+8\times8 \tag{2.1}
回想一下你的計算過程。大部分人會先計算出 4\times7 ,然後將結果存放在想象中的一個空間中,接著再將 8\times8 的結果放入同一個空間中。最後在這個想象的空間中,將兩個結果相加得到最終的答案。
這個想象的「空間」,也就是工作記憶《working memory》,在上述任務中直接決定了你的心算能力。工作記憶在這個任務中發揮了兩個作用。一方面,它將任務拆分成子任務,規劃完成任務所需的步驟。任務規劃是指完成一個任務需要完成多個子任務,因此需要一定的任務規劃能力。任務規劃的過程可能也是在工作記憶中完成的。例如,在這個問題中,應該先分別計算兩個乘法的和,再將結果相加。除此之外,許多推理問題也需要任務規劃能力,因為推理通常涉及多個步驟,需要規劃好每一步推理要做的事情。另一方面,在工作記憶中人類可以修改計算的中間結果,以確保最終的輸出結果的準確性。
遺憾的是,目前 ChatGPT 的神經網路結構和訓練方式決定了它的工作記憶相對較小,這也可能解釋為什麼 ChatGPT 不太擅長做計算和任務規劃。

雖然 ChatGPT 的工作記憶有時候受限,但並不意味著我們沒有緩解這個限制的方法。
2.2.2 如何增加工作記憶
同樣的,如果讓你計算下面的算式:
4\times7+8\times8 \tag{2.2}
如果讓你用筆和紙,你可以輕易的得出正確答案。筆和紙將計算和推理的中間過程記錄了下來,它極大的減少了我們對工作記憶的占用。
同樣的,我們可以用提示《prompt》來引導 ChatGPT 將中間步驟都記錄下來,以減少它對工作記憶的占用,進而減少它犯錯的幾率。

這種引導方式被稱為 思維鏈提示 《Chain of Thought》。實際上,除了思維鏈提示外,研究者還提出了 ReAct 提示和 self ask 提示。它們的本質思想都是通過設計提示來減少ChatGPT對工作記憶的負擔。稍有不同的是,ReAct 和 self ask 進一步引入了外部工具,這將在後面的章節中進行講解。
2.3 短期記憶
2.3.1 什麼是短期記憶
實際上,ChatGPT 模型是 無狀態 的。每次我們調用 OpenAI 的接口並開始與ChatGPT 進行對話時,我們都開始了一次全新的對話,我們通常將這個對話稱為 會話。那麼,為什麼用戶會感覺到 ChatGPT 記得前面的互動內容呢?
其實這點我們在 1.3.1 小節做了解讀。ChatGPT 每次的輸入是用戶之前多輪對話的歷史,這些歷史就是輸入的提示《prompt》,從而讓用戶感覺 ChatGPT 在和他進行連續的對話。

多輪對話的歷史,我們常稱為 短期記憶,它可以視為提示《prompt》的一部分。短期記憶可以幫我們塑造不同性格和能力的 ChatGPT。雖然大家使用的 ChatGPT 的參數都是同樣的,但不同的短期記憶能把 ChatGPT 「調教」成不同的性格,塑造成不同的工具。
讓我們做一個不太恰當的類比,幫助讀者進一步理解短期記憶。小吳是剛畢業的大學生,通過二十幾年的教育和學習,他掌握了很多的知識,這些知識好比 ChatGPT 的參數,已經牢牢存儲在了他的腦裡,形成了各種能力。當踏上工作崗位後,他需要快速掌握一些工具,他工作中的師傅通過和他的對話和互動將這些知識傳授給了他,這些知識還未牢牢存儲在他的腦裡,而是存儲在短期記憶中。
2.3.2 短期記憶的問題
短期記憶確實可以幫助我們打造不同性格和能力的 ChatGPT,但是存在兩個問題:
這裡稍微說明一下 OpenAI 的計費方法。OpenAI 主要根據 token 的消耗量計費,消耗的 token 越多,花的錢越多。消耗的 token 來自兩個地方:
2.3.3 如何解決短期記憶的問題
要解決短期記憶持續膨脹的問題,可以采取盡可能減少短期記憶 token 數量的方法。但是需要確保盡可能保留短期記憶的核心內容。通常有以下幾種方法來解決短期記憶問題。
方案一:
選擇一個窗口,隻保留最近 k 輪對話內容。

這個策略基於如下假設:過於久遠的對話不太重要,而距離當前時間更近的對話則更加重要。
方案二:
利用大型語言模型強大的文本摘要能力,將對話歷史和新增的互動內容進行摘要提取。

例如你可以開啟另外一個和 ChatGPT 的會話,這個會話的目的是對你目前正在使用的會話進行文本摘要提取。

甚至我們在用大型語言模型給對話歷史做摘要的時候,還可以設定要求,要求它把生成的 token 數量控制在一定范圍內,這樣我們就能和 ChatGPT 永遠對話下去。但需要注意的是,隨著對話輪數的增多,必然有一部分信息會被過濾掉。
方案三:
將方案一和方案二結合起來,隻對最近 k 輪對話進行文本摘要的提取。這進一步的壓縮了短期記憶的 token 數。
方案四:
設計一些更復雜的短期記憶壓縮方案。例如通過實體抽取將對話中的重要實體和內容抽取出來,利用知識圖譜將對話中的關系對組織出來等等。
方案四涉及到更復雜的提示工程,也涉及到自然語言處理的一些基本知識,對這部分感興趣讀者可以參考 LangChain 中 ConversationEntityMemory 和 ConversationKGMemory 的實現 [②]。
2.4 長期記憶
2.4.1 什麼是長期記憶
長期記憶是短期記憶的相對概念。短期記憶的生命周期隻存在於一次會話中,當會話完全結束後,短期記憶就不存在了。而長期記憶可以一直存儲和訪問。就像人類大腦會對一些重要信息進行長期記憶一樣。
實現長期記憶最好的方法是將整個大型語言模型進行 finetune,將您想要它記住和理解的內容調整到模型的權重中。
然而,finetune 會帶來兩個挑戰。一方面,finetune 對數據量有一定的要求,數據量過小難以獲得好的效果。另一方面,finetune 對算力的要求非常高。目前,OpenAI 尚未開放 ChatGPT 針對自定義數據集的 finetune。但我相信 OpenAI 遲早會開放這個功能。
那麼,除了 finetune,還有其他的方法來存儲長期記憶嗎?答案是有的。最簡單的方法是將長期記憶存儲在外部數據庫中,當與 ChatGPT 開始對話時,從數據庫中提取長期記憶,並將其作為提示(prompt)輸入到 ChatGPT 中。
這種方法理論上可以解決長期記憶的問題,本質上是通過上下文學習完全代替 finetune。但是這種方法存在一個嚴重的缺陷,因為 ChatGPT 的神經網路結構決定它隻能處理最多 4096 個 token。而長期記憶通常涉及到非常多的 token,例如用戶編寫的工程代碼、用戶想要 ChatGPT 記住的文檔,甚至是書籍等等。
2.4.2 如何間接存儲長期記憶
實際上,我們有更巧妙的方法來解決前面小節提到的問題。解決方法的思路非常類似於推薦系統中的召回策略。
假設我們希望 ChatGPT 記住的長期記憶是一個文檔,首先我們將文檔進行分片,將文檔拆分成一份份的,每一份的 token 數不會太大,以保證每一份都能完全塞入 ChatGPT 中。

緊接著我們利用神經網路 [③] 將每一份文檔進行編碼。這個神經網路輸入的是文檔,輸出的是一個向量編碼。這個向量編碼可以理解為神經網路對文檔內容進行了高度的壓縮。然後我們將編碼的結果存儲在 向量數據庫 中。
向量數據庫是一種特殊的數據庫,它的鍵是向量而不是一個數。在我們的場景下,這個向量數據庫的鍵是文檔的向量,對應的值是對應的文檔。

到目前為止準備工作已經準備就緒。接下來我們將演示如何通過這套系統完成 間接的長期記憶。
當用戶向 ChatGPT 提出一個問題時,我們先將他的提問文本塞入到之前的神經網路中,該神經網路將用戶的提問編碼成向量。然後將編碼的向量去向量數據庫中查詢,查詢的結果是和提問編碼向量最接近的向量《這裡的接近一般是指向量的餘弦相似度或歐氏距離》。然後我們將查詢到的向量對應的文檔作為提示《prompt》給到 ChatGPT,至此我們完成了長期記憶的查詢。
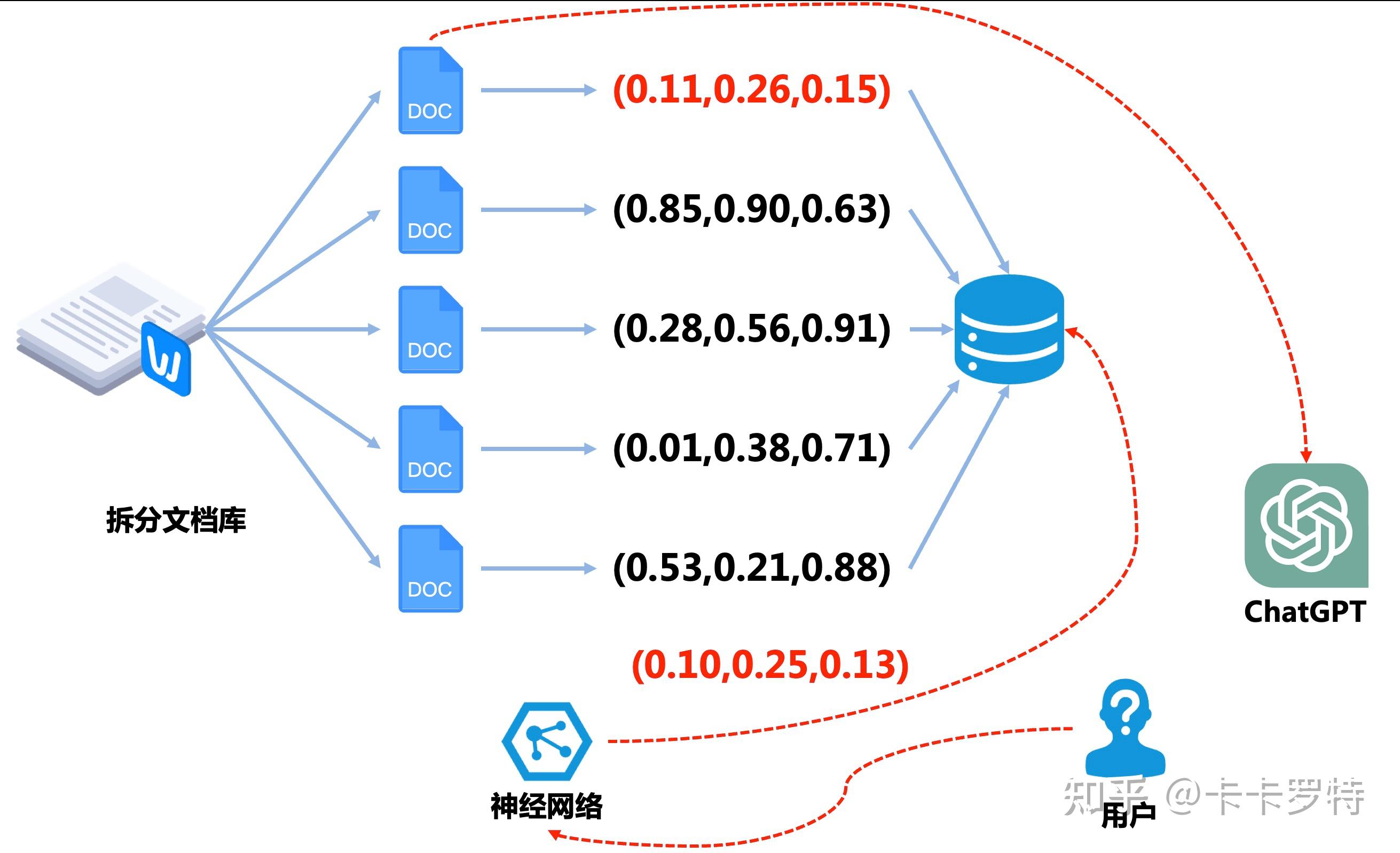
例如在上圖中,用戶的提問被編成成 (0.10,0.25,0.13) ,在向量數據庫中,查詢到最接近的向量是 (0.11,0.26,0.15) ,對應的文檔是第一個子文檔。
不難看到,這種思路是根據用戶的提問召回相關的文檔。然後將文檔加工成對應的提示給到 ChatGPT,然後讓 ChatGPT 完成後續的任務。
2.5 外部工具
2.5.1 為什麼需要外部工具
一方面使用工具是具有智能的表現之一,另一方面雖然人類擁有智能,但並不擅長所有的任務,例如,準確計算大量數字或快速查詢大量文檔都是相對較為困難的任務。對於 ChatGPT 這樣的大型語言模型也是如此,它雖然具備強大的語言處理能力,但並不擅長進行符號計算、實時信息獲取或代碼的執行。
正是由於 ChatGPT 在某些任務上表現不佳,因此我們需要讓它學會使用外部工具,以使其變得更加強大。
除此之外,我們需要認識到 ChatGPT 的真正優勢所在。它的強大之處並不在於總能夠給出準確無誤的答案,相反,ChatGPT 有時會說一些無關緊要的話。ChatGPT 真正的優勢在於其能夠清晰地理解以自然語言給出的指令。因此,基於這一特性,我們可以讓 ChatGPT 充當中央控制器,自動查找適合的工具,並在適當的時候使用它們。例如,當 ChatGPT 需要進行數字計算時,我們可以讓它自動調用計算器程序進行輔助計算。同樣地,當 ChatGPT 無法實時獲取最新消息和信息時,我們可以讓它使用搜索引擎搜索實時新聞和信息。另外,如果 ChatGPT 無法模擬運行非常復雜的代碼,我們可以讓它調用相應的解釋器、編譯器或虛擬機。
熟悉強化學習的讀者可以看出,當 ChatGPT 使用外部工具時,我們可以將其視為強化學習中的智能體 agent,通過與 環境 交互以實現任務。
2.5.2 如何使用外部工具
在講解兩種具體方法之前,我們首先說明一下 ChatGPT 使用外部工具的整體思路。

首先,我們需要設計一個提示,這個提示包含了解決問題的步驟和工具的使用。接著我們提出我們要解決的問題,將提示和問題一起給到 ChatGPT。
然後 ChatGPT 會開始生成文本。其中會出現使用某個工具的 token。例如 搜索(三體的作者是誰) 。當出現了使用工具的 token 後,ChatGPT 停止文本生成。根據事先寫好的接口開始使用工具。例如調用搜索引擎的接口搜索 三體的作者是誰。
接著工具的結果返回給 ChatGPT ,並和前文的內容組成新的提示《Prompt》發送給 ChatGPT。
最後 ChatGPT 根據新的提示《Prompt》再次生成文本,開始重復前面的步驟。不斷重復直到 ChatGPT 停止使用工具得到最終的答案。
下面我們講解兩個經典的使用外部工具的例子,分別是 ReAct 框架和 self-ask 框架,它們都屬於使用工具的提示工程。
由於這兩個框架的提示都是用的英文,為了方便復現,我們以英文的對話為例《這裡主要參考 LangChain 庫》。
ReAct 框架:
ReAct 是 Resoning 和 Acting 的縮寫。這個框架的基本思想是給一個 Prompt,這個 Prompt 將 Question 拆成幾個步驟。分別是:
- Tought: 面對這個 Question 我下一步應該做什麼。
- Action:執行某個動作。在 ReAct 裡有三種動作,第一個是 Search[entity] 如果存在對應實體的維基頁面,則返回前5句話,否則使用維基百科搜索引擎搜索前5個類似的實體;第二個是 Look[sring] 它將返回包含該字符串的頁面中的下一句話,模擬瀏覽器上的 Ctrl+F 功能。第三個是 Finish[answer] 它將使用答案完成當前任務。
- Observation:觀察到的外部工具給到的結果,將作為新的提示輸入給 ChatGPT。
在 LangChain 中 ReAct 框架的提示如下:
Question: What is the elevation range for the area that the eastern sector of theColorado orogeny extends into?Thought 1: I need to search Colorado orogeny,find the area that the eastern sectorof the Colorado orogeny extends into,then find the elevation range of thearea.Action 1: Search[Colorado orogeny]Observation 1: The Colorado orogeny was an episode of mountain building (an orogeny) inColorado and surrounding areas.Thought 2: It does not mention the eastern sector. So I need to look up easternsector.Action 2: Lookup[eastern sector]Observation 2: (Result 1 / 1) The eastern sector extends into the High Plains and is calledthe Central Plains orogeny.Thought 3: The eastern sector of Colorado orogeny extends into the High Plains. So Ineed to search High Plains and find its elevation range.Action 3: Search[High Plains]Observation 3: High Plains refers to one of two distinct land regionsThought 4: I need to instead search High Plains (United States).Action 4: Search[High Plains (United States)]Observation 4: The High Plains are a subregion of the Great Plains. From east to west,theHigh Plains rise in elevation from around 1,800 to 7,000 ft (550 to 2,130m).[3]Thought 5: High Plains rise in elevation from around 1,800 to 7,000 ft,so the answeris 1,800 to 7,000 ft.Action 5: Finish[1,800 to 7,000 ft]Question: Musician and satirist Allie Goertz wrote a song about the "The Simpsons"character Milhouse,who Matt Groening named after who?Thought 1: The question simplifies to "The Simpsons" character Milhouse is named afterwho. I only need to search Milhouse and find who it is named after.Action 1: Search[Milhouse]Observation 1: Milhouse Mussolini Van Houten is a recurring character in the Fox animatedtelevision series The Simpsons voiced by Pamela Hayden and created by MattGroening.Thought 2: The paragraph does not tell who Milhouse is named after,maybe I can look up"named after".Action 2: Lookup[named after]Observation 2: (Result 1 / 1) Milhouse was named after U.S. president Richard Nixon,whosemiddle name was Milhous.Thought 3: Milhouse was named after U.S. president Richard Nixon,so the answer isRichard Nixon.Action 3: Finish[Richard Nixon]Question: Which documentary is about Finnish rock groups,Adam Clayton Powell or TheSaimaa Gesture?Thought 1: I need to search Adam Clayton Powell and The Saimaa Gesture,and find whichdocumentary is about Finnish rock groups.Action 1: Search[Adam Clayton Powell]Observation 1 Could not find [Adam Clayton Powell]. Similar: [’Adam Clayton PowellIII’,’Seventh Avenue (Manhattan)’,’Adam Clayton Powell Jr. State OfficeBuilding’,’Isabel Washington Powell’,’Adam Powell’,’Adam Clayton Powell(film)’,’Giancarlo Esposito’].Thought 2: To find the documentary,I can search Adam Clayton Powell (film).Action 2: Search[Adam Clayton Powell (film)]Observation 2: Adam Clayton Powell is a 1989 American documentary film directed byRichard Kilberg. The film is about the rise and fall of influentialAfrican-American politician Adam Clayton Powell Jr.[3][4] It was later airedas part of the PBS series The American Experience.Thought 3: Adam Clayton Powell (film) is a documentary about an African-Americanpolitician,not Finnish rock groups. So the documentary about Finnish rockgroups must instead be The Saimaa Gesture.Action 3: Finish[The Saimaa Gesture]Question: What profession does Nicholas Ray and Elia Kazan have in common?Thought 1: I need to search Nicholas Ray and Elia Kazan,find their professions,thenfind the profession they have in common.Action 1: Search[Nicholas Ray]Observation 1: Nicholas Ray (born Raymond Nicholas Kienzle Jr.,August 7,1911 – June 16,1979) was an American film director,screenwriter,and actor best known forthe 1955 film Rebel Without a Cause.Thought 2: Professions of Nicholas Ray are director,screenwriter,and actor. I needto search Elia Kazan next and find his professions.Action 2: Search[Elia Kazan]Observation 2: Elia Kazan was an American film and theatre director,producer,screenwriterand actor.Thought 3: Professions of Elia Kazan are director,producer,screenwriter,and actor.So profession Nicholas Ray and Elia Kazan have in common is director,screenwriter,and actor.Action 3: Finish[director,screenwriter,actor]Question: Which magazine was started first Arthur’s Magazine or First for Women?Thought 1: I need to search Arthur’s Magazine and First for Women,and find which wasstarted first.Action 1: Search[Arthur’s Magazine]Observation 1: Arthur’s Magazine (1844-1846) was an American literary periodical publishedin Philadelphia in the 19th century.Thought 2: Arthur’s Magazine was started in 1844. I need to search First for Womennext.Action 2: Search[First for Women]Observation 2: First for Women is a woman’s magazine published by Bauer Media Group in theUSA.[1] The magazine was started in 1989.Thought 3: First for Women was started in 1989. 1844 (Arthur’s Magazine) < 1989 (Firstfor Women),so Arthur’s Magazine was started first.Action 3: Finish[Arthur’s Magazine]Question: Were Pavel Urysohn and Leonid Levin known for the same type of work?Thought 1: I need to search Pavel Urysohn and Leonid Levin,find their types of work,then find if they are the same.Action 1: Search[Pavel Urysohn]Observation 1: Pavel Samuilovich Urysohn (February 3,1898 – August 17,1924) was a Sovietmathematician who is best known for his contributions in dimension theory.Thought 2: Pavel Urysohn is a mathematician. I need to search Leonid Levin next andfind its type of work.Action 2: Search[Leonid Levin]Observation 2: Leonid Anatolievich Levin is a Soviet-American mathematician and computerscientist.Thought 3: Leonid Levin is a mathematician and computer scientist. So Pavel Urysohnand Leonid Levin have the same type of work.Action 3: Finish[yes]Question: Author David Chanoff has collaborated with a U.S. Navy admiral who served as the ambassador to the United Kingdom under which President?