作者:eliotzhou,騰訊 IEG 數據分析工程師
前言
比爾·蓋茨說:『chatgpt像互聯網發明一樣重要,將會改變世界。』使用一段時間chatgpt後,可以發現chatgpt是能極大的提高工作效率的工具。在遊戲運營中,數據分析和數據科學是非常重要的一環。
有了chatgpt,對於不會數據分析技能的運營同學,也可以進行常見的數據分析,作為工作效率的極大提升。對於會數據分析的運營同學和專職數據分析同學,可以使用chatgpt替代日常中數據分析開發工作,將重心更多的聚焦分析和業務工作。
本文就列舉了4種常見的遊戲運營中的數據分析場景,包括數據提取,數據分析,聚類,預測等,使用chatgpt輔助完成分析工作。
在使用chatGPT的過程中,我也會思考,有了chatgpt,好像我們的工作內容有一部分被取代了,是否說明我們的價值也相應被取代了呢?
我認為未來的時代,我們確實應該和chatgpt一樣,持續進化。作為一個數據分析師或者遊戲運營的價值,應該體現在:
- 更深的業務理解能力
- 更廣的知識體系和知識運用能力《分析能力,算法能力,心理學,社會學,經濟學》
- 數據敏感度和創造力
- 更熟練的chatgpt使用能力
提取數據
提取數據是非常常見的工作,這裡介紹了如何使用chatgpt輔助生成提取數據sql代碼。
準備工作
輸入要用到的表和字段,這些信息可以詢問數據同學。舉個例子,這裡用到三張數據表:
用戶登錄表eliot_db::yuanshen_userlogin,表是靜態分區表,分區字段datadate,包括字段:userid,登錄時間logdate 用戶付費表eliot_db::yuanshen_userpay,表是靜態分區表,分區字段datadate,包括字段:userid,最近7天付費金額weekpaymoney 用戶信息表eliot_db::yuanshen_userinfo,表是靜態分區表,分區字段datadate,包括字段:userid,年齡iage
輸入chatgpt:

描述提取需求
我們想要提取最近30天活躍用戶,包括每個用戶的最近7天付費金額,和年齡信息。然後過濾18歲以下用戶。可以這麼輸入chatgpt:

chatgpt輸出的hive代碼:
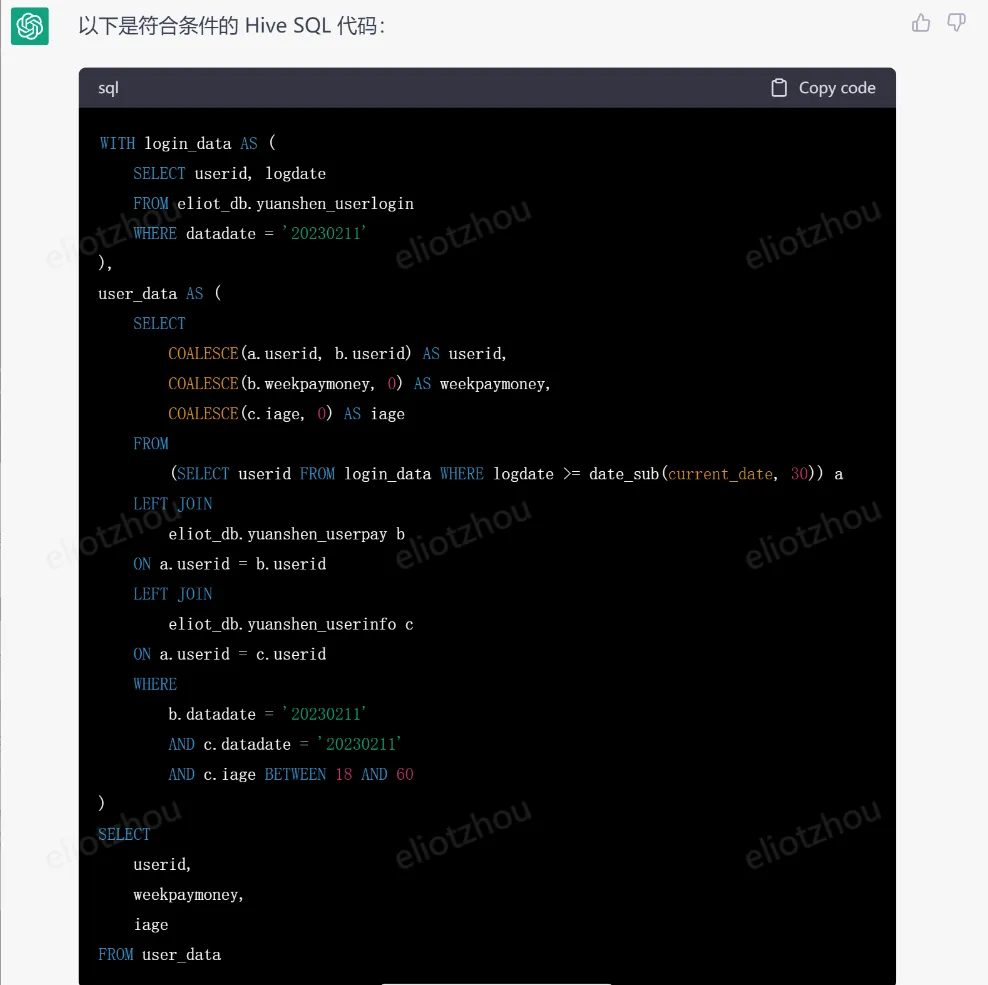
如果你具備一定的hive代碼能力,檢查下代碼。以上chatgpt給出的代碼完全沒有問題。
在idex中執行代碼
將代碼復制到idex中,執行代碼,等待結果:

檢查錯誤
有時候代碼執行會報錯,可以直接把錯誤信息讓chatgpt查詢

復制紅字部分,輸入給chatgpt

報錯原因是因為表名或者庫名不對,可以檢查核對後,修改一下代碼。
數據分析
數據分析也是比較常見的工作,包括遊戲用戶群的各項指標的分佈和趨勢等。同樣的,我們可以讓chatgpt生成分析代碼。
用戶付費能力分佈
我們想要看特定用戶付費金額分佈情況,比如用戶范圍是最近30天活躍過的用戶,年齡18~60歲。看最近7天付費金額分佈情況,按每10元一個區間劃分分佈。
這裡有一個需要明確的需求點要指明給chatgpt:如果我們取最近30天活躍過的用戶,那麼用戶最近7天沒有付費,不能把這部分過濾掉,將付費金額設置為0。
將需求輸入給chatgpt:

chatgpt返回的hive代碼:
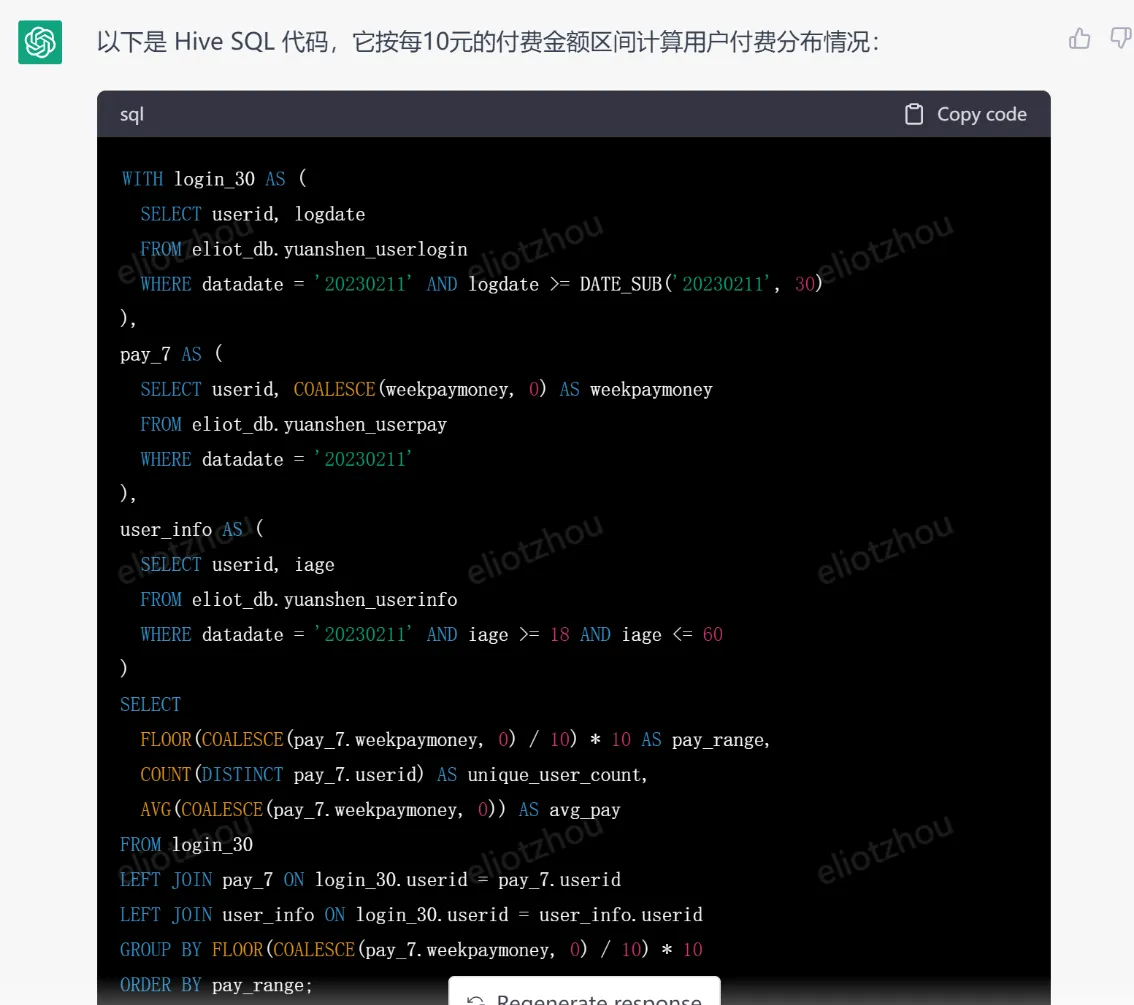
這個代碼檢查一下,也是完全沒問題的,在idex執行就行。
得到結果後我們想檢驗下結果是否正確,可以將所有付費分佈的用戶數加和,得到我們定義的用戶范圍的用戶數。
然後輸入一個求用戶數的代碼需求給chatgpt:
 WeChatWorkScreenshot_849e9956-8ce9-4293-b004-ce8648550248
WeChatWorkScreenshot_849e9956-8ce9-4293-b004-ce8648550248
對比兩個用戶數,無誤說明之前我們的需求結果應該沒問題。
不同年齡段用戶的付費能力分佈情況
進一步,我們計算一個更復雜的分佈問題,假如我們想看不同年齡段的用戶的付費區間分佈情況,我們繼續輸入需求:
 WeChatWorkScreenshot_868f8ee1-02e2-49d7-9b37-ccd956acfe73
WeChatWorkScreenshot_868f8ee1-02e2-49d7-9b37-ccd956acfe73
chatgpt給出的hive代碼:

同樣的在idex執行代碼,然後核對檢查下。
聚類
聚類是我們做遊戲用戶畫像工作中常用的方法,比如用戶玩法偏好,付費偏好等等。這裡,我們用chatgpt輔助生成聚類代碼。
聚類之前,需要準備好用戶特征表,可以用之前列舉的用戶提取和分析方法,讓chatgpt生成代碼,跑出用戶包文件。
舉一個例子,我們想看原神用戶玩法偏好畫像,我們可以根據我們對遊戲業務的理解能力,生成這樣的一張用戶特征表:
userid,主線劇情推進度zhuxian_rate,支線任務完成數renwu_num,深淵獲得星數shenyuan_num,大地圖探索度ditu_rate,七聖召喚比賽數zhaohuan_num。
生成聚類代碼
輸入需求:

chatgpt生成的代碼:


檢查了代碼,基本沒有問題。
執行聚類代碼
點開idex,打開jupyter:

選擇python3.7新建一個啟動頁,重命名為yuanshen_kmeans.ipynb,將代碼復制進去

然後將用戶表文件放到目錄中:
 WeChatWorkScreenshot_449ecd96-b7ed-44e8-88aa-4a11f6189a37
WeChatWorkScreenshot_449ecd96-b7ed-44e8-88aa-4a11f6189a37
最後點擊執行,等待輸出聚類結果。
解讀結果
得到聚類結果後,我們會進一步分析用戶畫像,比如我們可以關聯輸出的聚類結果用戶包,分析每個類別用戶的其他特征指標情況等。
我們還需要分析每個類別用戶的這些主要特征指標聚心結果,基於遊戲業務理解,描述用戶畫像。
我一時興起,將聚類結果輸入給了chatgpt,請它幫忙描述下每類用戶的畫像。

它概括的居然還不錯
 WeChatWorkScreenshot_e2097d0d-e087-47b0-b6a9-04c6bc331ca6
WeChatWorkScreenshot_e2097d0d-e087-47b0-b6a9-04c6bc331ca6
預測
預測也是我們在遊戲數據分析工作中經常會遇見的工作場景,包括道具銷量預測,KPI指標預測,用戶流失預測等等。
我們可以讓chatgpt生成預測工作全過程的代碼,幫忙我們快速得到預測結果。
舉個例子,我們想預測原神1個月後上線的復刻胡桃和夜蘭的池子流水收人,我們需要先準備兩部分數據:
1.歷史上線的角色池子收入數據yuanshen_juese_water_data.csv,和對應的每個池子的特征字段數據,比如:用戶活躍數actusers,用戶付費payusermoney,角色屬性juese_feature_id,已擁有角色用戶數have_juese_users等。
2.需要預測的池子的特征字段數據yuanshen_juese_water_predict.csv,用戶活躍數,用戶付費,角色屬性,已擁有角色用戶數等。
生成預測代碼
輸入需求

chatgpt給出的代碼
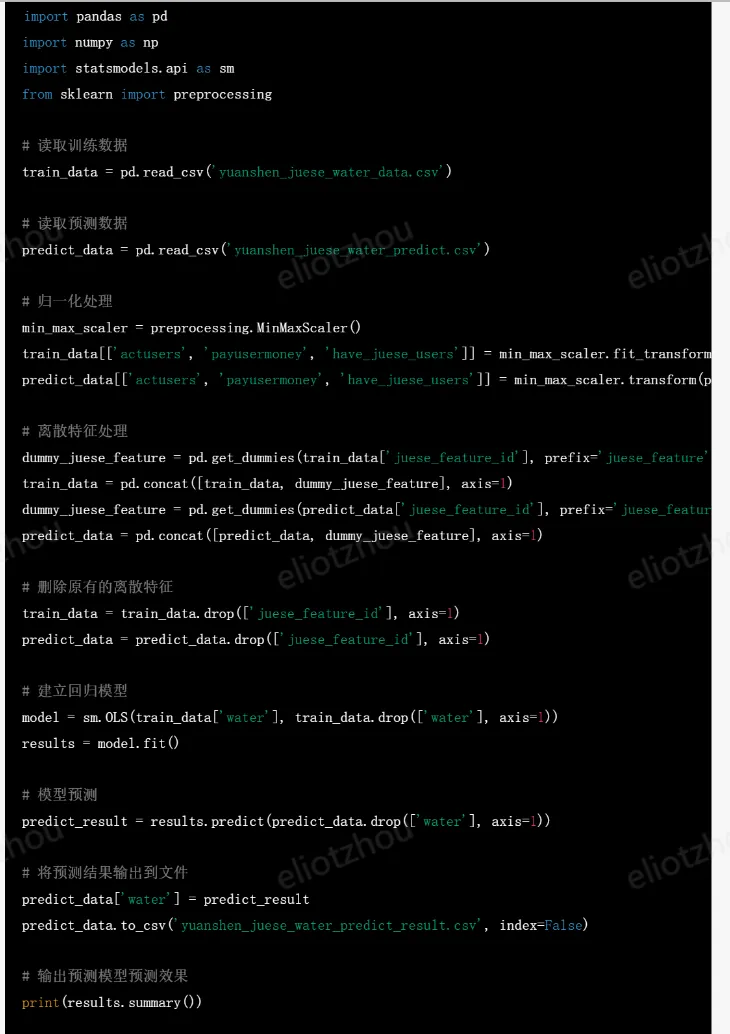
執行代碼並評估效果
執行代碼後,輸出了預測結果,可以用於評估待上線的角色池子的流水水平。
當然,我們需要評估預測模型的準確度是否在我們的誤差承受范圍內,因此我們需要分析下模型效果。

模型看上去是比較準確的,並且通過回歸模型,我們可以發現,角色的屬性信息,是比較能影響角色池子流水收人的。
因此,這個特征是在商業化探索上值得我們進一步分析的。
因果推斷
更進一步,我們在工作中也會有一些因果推斷的問題,比如分析某個策略或指標對用戶留存,活躍的影響等等。
簡單的因果推斷問題,我們也可以讓chatgpt快速生成代碼。
舉個例子,我們想分析釣魚這種休閑玩法,是否能促進玩家的在線時長,我們需要先準備這樣的數據:
用戶特征數據yuanshen_user_diaoyu_feature_data.csv,包括字段:vopenid,是否參與釣魚玩法is_diaoyu,最近7天在線時長onlinetime,過去7天在線時長week_onlinetime,註冊時間regdate等
生成PSM代碼
輸入需求

chatgpt給出的代碼:

這裡我們首先加載數據到一個 Pandas DataFrame 中,並將幹預變量、結果變量和控制變量分別保存到變量 treatment、outcome 和 covariates 中。
接著,我們使用 StandardScaler 將連續變量進行標準化,然後創建一個 CausalModel 對象並指定這些變量。使用 est_propensity_s 方法估計傾向得分,使用 est_via_matching 方法進行匹配,然後使用 summary_stats 屬性輸出平衡性檢驗結果。
接下來,我們從匹配後的樣本中獲取數據,並計算兩組用戶的均值差作為幹預效應。最後,我們計算均方誤差《MSE》作為指標評估 PSM 分析結果。
在這個例子中,我們關注最近7天在線時長的平均值,因此可以使用 MSE 作為評估指標,其結果越小越好。
值得注意的是,我們這裡采用的是均值差作為幹預效應的度量方式。這種度量方式有時會存在偏差,因為兩組用戶之間可能存在一些差異,導致均值差並不能完全反映幹預效應。更好的做法是將幹預效應視為一個連續變量,並使用回歸模型來擬合該效應,從而更準確地評估幹預效應的大小。這裡的代碼也可以相應地進行修改,將幹預效應視為連續變量進行擬合。